Strain
Human_SARS_EU371560
(Region: China; Strain: SARS coronavirus BJ182a, complete genome.; Date: 2003)
Gene
orf1a polyprotein
Description
Annotated in NCBI,
orf1a polyprotein
Location
GenBank Accession
Full name
Replicase polyprotein 1a
Alternative Name
ORF1a polyprotein
Sequence
CDS
ATGGAGAGCCTTGTTCTTGGTGTCAACGAGAAAACACACGTCCAACTCAGTTTGCCTGTCCTTCAGGTTAGAGACGTGCTAGTGCGTGGCTTCGGGGACTCTGTGGAAGAGGCCCTATCGGAGGCACGTGAACACCTCAAAAATGGCACTTGTGGTCTAGTAGAGCTGGAAAAAGGCGTACTGCCTCAGCTTGAACAGCCCTATGTGTTCATTAAACGTTCTGATGCCTTACGCACCAATCACGGCCACAAGGTCGTTGAGCTGGTTGCAGAAATGGACGGCATTCAGTACGGTCGTAGCGGTATAACACTGGGAGTACTCGTGCCACATGTGGGCGAAACCCCAATTGCATACCGCAATGTTCTTCTTCGTAAGAACGGTAATAAGGGAGCCGGTGGTCATAGCTATGGCATCGATCTAAAGTCTTATGACTTAGGTGACGAGCTTGGCACTGATCCCATTGAAGATTATGAACAAAACTGGAACACTAAGCATGGCAGTGGTGCACTCCGTGAACTCACTCGTGAGCTCAATGGAGGTGCAGTCACTCGCTATGTCGACAACAATTTCTGTGGCCCAGATGGGTACCCTCTTGATTGCATCAAAGATTTTCTCGCACGCGCGGGCAAGTCAATGTGCACTCTTTCCGAACAACTTGATTACATCGAGTCGAAGAGAGGTGTCTACTGCTGCCGTGACCATGAGCATGAAATTGCCTGGTTCACTGAGCGCTCTGATAAGAGCTACGAGCACCAGACACCCTTCGAAATTAAGAGTGCCAAGAAATTTGACACTTTCAAAGGGGAATGCCCAAAGTTTGTGTTTCCTCTTAACTCAAAAGTCAAAGTCATTCAACCACGTGTTGAAAAGAAAAAGACTGAGGGTTTCATGGGGCGTATACGCTCTGTGTACCCTGTTGCATCTCCACAGGAGTGTAACAATATGCACTTGTCTACCTTGATGAAATGTAATCATTGCGATGAAGTTTCATGGCAGACGTGCGACTTTCTGAAAGCCACTTGTGAACATTGTGGCACTGAAAATTTAGTTATTGAAGGACCTACTACATGTGGGTACCTACCTACTAATGCTGTAGTGAAAATGCCATGTCCTGCCTGTCAAGACCCAGAGATTGGACCTGAGCATAGTGTTGCAGATTATCACAACCACTCAAACATTGAAACTCGACTCCGCAAGGGAGGTAGGACTAGATGTTTTGGAGGCTGTGTGTTTGCCTATGTTGGCTGCTATAATAAGCGTGCCTACTGGGTTCCTCGTGCTAGTGCTGATATTGGCTCAGGCCATACTGGCATTACTGGTGACAATGTGGAGACCTTGAATGAGGATCTCCTTGAGATACTGAGTCGTGAACGTGTTAACATTAACATTGTTGGCGATTTTCATTTGAATGAAGAGGTTGCCATCATTTTGGCATCTTTCTCTGCTTCTACAAGTGCCTTTATTGACACTATAAAGAGTCTTGATTACAAGTCTTTCAAAACCATTGTTGAGTCCTGCGGTAACTATAAAGTTACCAAGGGAAAGCCCGTAAAAGGTGCTTGGAACATTGGACAACAGAGATCAGTTTTAACACCACTGTGTGGTTTTCCCTCACAGGCTGCTGGTGTTATCAGATCAATTTTTGCGCGCACACTTGATGCAGCAAACCACTCAATTCCTGATTTGCAAAGAGCAGCTGTCACCATACTTGATGGTATTTCTGAACAGTCATTACGTCTTGTTGACGCCATGGTTTATACTTCAGACCTGCTCACCAACAGTGTCATTATTATGGCATATGTAACTGGTGGTCTTGTACAACAGACTTCTCAGTGGTTGTCTAATCTTTTGGGCACTACTGTTGAAAAACTCAGGCCTATCTTTGAATGGATTGAGGCGAAACTTAGTGCAGGAGCTGAATTTCTCAAGGATGCTTGGGAGATTCTCAAATTTCTCATTACAGGTGTTTTTGACATCGTCAAGGGTCAAATACAGGTTGCTTCAGATAACATCAAGGATTGTGTAAAATGCTTCATTGATGTTGTTAACAAGGCACTCGAAATGTGCATTGATCAAGTCACTATCGCTGGCGCAAAGTTGCGATCACTCAACTTAGGTGAAGTCTTCATCGCTCAAAGCAAGGGACTTTACCGTCAGTGTATACGTGGCAAGGAGCAGCTGCAACTACTCATGCCTCTTAAGGCACCAAAAGAAGTAACCTTTCTTGAAGGTGATTCACATGACACAGTACTTACCTCTGAGGAGGTTGTTCTCAAGAACGGTGCACTCGAAGCACTCGAGACGCCCGTTGATAGCTTCACAAATGGAGCTATCGTTGGCACACCAGTCTGTGTAAATGGCCTCATGCTCTTAGAGATTAAGGACAAAGAACAATACTGCGCATTGTCTCCTGGTTTACTGGCTACAAACAATGTCTTTCGCTTAAAAGGGGGTGCACCAATTAAAGGTGTAACCTTTGGAGAAGATACTGTTTGGGAAGTTCAAGGTTACAAGAATGTGAGAATCACATTTGAGCTTGATGAACGTGTTGACAAAGTGCTTAATGAAAAGTGCTCTGTCTACACTGTTGAATCCGGTACCGAAGTTACTGAGTTTGCATGTGTTGTAGCAGAGGCTGTTGTGAAGACTTTACAACCAGTTTCTGATCTCCTTACCAACATGGGTATTGATCTTGATGAGTGGAGTGTAGCTACATTCTACTTATTTGATGATGCTGGTGAAGAAAACTTTTCATCACGTATGTATTGTTCCTTTTACCCTCCAGATGAGGAAGAAGAGGACGATGCAGAGTGTGAGGAAGAAGAAATTGATGAAACCTGTGAACATGAGTACGGTACAGAGGATGATTATCAAGGTCTCCCTCTGGAATTTGGTGCCTCAGCTGAAACAGTTCGAGTTGAGGAAGAAGAAGAGGAAGACTGGCTGGATGATACTACTGAGCAATCAGAGATTGAGCCAGAACCAGAACCTACACCTGAAGAACCAGTTAATCAGTTTACTGGTTATTTAAAACTTACTGACAATGTTGCCATTAAATGTGTTGACATCGTTAAGGAGGCACAAAGTGCTAATCCTATGGTGATTGTAAATGCTGCTAACATACACCTGAAACATGGTGGTGGTGTAGCAGGTGCACTCAACAAGGCAACCAATGGTGCCATGCAAAAGGAGAGTGATGATTACATTAAGCTAAATGGCCCTCTTACAGTAGGAGGGTCTTGTTTGCTTTCTGGACATAATCTTGCTAAGAAGTGTCTGCATGTTGTTGGACCTAACCTAAATGCAGGTGAGGACATCCAGCTTCTTAAGGCAGCATATGAAAATTTCAATTCACAGGACATCTTACTTGCACCATTGTTGTCAGCAGGCATATTTGGTGCTAAACCACTTCAGTCTTTACAAGTGTGCGTGCAGACGGTTCGTACACAGGTTTATATTGTAGTCAATGACAAAGCTCTTTATGAGCAGGTTGTCATGGATTATCTTGATAACCTGAAGCCTAGAGTGGAAGCACCTAAACAAGAGGAGCCACCAAACACAGAAGATTCCAAAACTGAGGAGAAATCTGTCGTACAGAAGCCTGTCGATGTGAAGCCAAAAATTAAGGCCTGCATTGATGAGGTTACCACAACACTGGAAGAAACTAAGTTTCTTACCAATAAGTTACTCTTGTTTGCTGATATCAATGGTAAGCTTTACCATGATTCTCAGAACATGCTTAGAGGTGAAGATATGTCTTTCCTTGAGAAGGATGCACCTTACATGGTAGGTGATGTTATCACTAGTGGTGATATCACTTGTGTTGTAATACCCTCCAAAAAGGCTGGTGGCACTACTGAGATGCTCTCAAGAGCTTTGAAGAAAGTGCCAGTTGATGAGTATATAACCACGTACCCTGGACAAGGATGTGCTGGTTATACACTTGAGGAAGCTAAGACTGCTCTTAAGAAATGCAAATCTGCATTTTATGTACTACCTTCAGAAGCACCTAATGCTAAGGAAGAGATTCTAGGAACTGTATCCTGGAATTTGAGAGAAATGCTTGCTCATGCTGAAGAGACAAGAAAATTAATGCCTATATGCATGGATGTTAGAGCCATAATGGCAACCATCCAACGTAAGTATAAAGGAATTAAAATTCAAGAGGGCATCGTTGACTATGGTGTCCGATTCTTCTTTTATACTAGTAAAGAGCCTGTAGCTTCTATTATTACGAAGCTGAACTCTCTAAATGAGCCGCTTGTCACAATGCCAATTGGTTATGTGACACATGGTTTTAATCTTGAAGAGGCTGCGCGCTGTATGCGTTCTCTTAAAGCTCCTGCCGTAGTGTCAGTATCATCACCAGATGCTGTTACTACATATAATGGATACCTCACTTCGTCATCAAAGACATCTGAGGAGCACTTGGTAGAAACAGTTTCTTGGGCTGGCTCTTACAGAGATGGGTCCTATTCAGGACAGCGTACAGAGTTAGGTGTTGAATTTCTTAAGCGTGGTGACAAAATTGTGTACCACACTCTGGAGAGCCCCGTCGAGTTTCATCTTGACGGTGAGGTTCTTTCACTTGACAAACTAAAGAGTCTCTTATCCCTGCGGGAGGTTAAGACTATAAAAGTGTTCACAACTGTGGACAACACTAATCTCCACACACAGCTTGTGGATATGTCTATGACATATGGACAGCAGTTTGGTCCAACATACTTGGATGGTGCTGATGTTACAAAAATTAAACCTCATGTAAATCATGAGGGTAAGACTTTCTTTGTACTACCTAGTGATGACACACTACGTAGTGAAGCTTTCGAGTACTACCATACTCTTGATGAGAGTTTTCTTGGTAGGTACATGTCTGCTTTAAACCACACAAAGAAATGGAAATTTCCTCAAGTTGGTGGTTTAACTTCAATTAAATGGGCTGATAACAATTGTTATTTGTCTAGTGTTTTATTAGCACTTCAACAGCTTGAAGTCAAATTCAATGCACCAGCACTTCAAGAGGCTTATTATAGAGCCCGTGCTGGTGATGCTGCTAACTTTTGTGCACTCATACTCGCTTACAGTAATAAAACTGTTGGCGAGCTTGGTGATGTCAGAGAAACTATGACCCATCTTCTACAGCATGCTAATTTGGAATCTGCAAAGCGAGTTCTTAATGTGGTGTGTAAACATTGTGGTCAGAAAACTACTACCTTAACGGGTGTAGAAGCTGTGATGTATATGGGTACTCTATCTTATGATAATCTTAAGACAGGTGTTTCCATTCCATGTGTGTGTGGTCGTGATGCTACACAATATCTAGTACAACAAGAGTCTTCTTTTGTTATGATGTCTGCACCACCTGCTGAGTATAAATTACAGCAAGGTACATTCTTATGTGCGAATGAGTACACTGGTAACTATCAGTGTGGTCATTACACTCATATAACTGCTAAGGAGACCCTCTATCGTATTGACGGAGCTCACCTTACAAAGATGTCAGAGTACAAAGGACCAGTGACTGATGTTTTCTACAAGGAAACATCTTACACTACAACCATCAAGCCTGTGTCGTATAAACTCGATGGAGTTACTTACACAGAGATTGAACCAAAATTGGATGGGTATTATAAAAAGGATAATGCTTACTATACAGAGCAGCCTATAGACCTTGTACCAACTCAACCATTACCAAATGCGAGTTTTGATAATTTCAAACTCACATGTTCTAACACAAAATTTGCTGATGATTTAAATCAAATGACAGGCTTCACAAAGCCAGCTTCACGAGAGCTATCTGTCACATTCTTCCCAGACTTGAATGGCGATGTAGTGGCTATTGACTATAGACACTATTCAGCGAGTTTCAAGAAAGGTGCTAAATTACTGCATAAGCCAATTGTTTGGCACATTAACCAGGCTACAACCAAGACAACGTTCAAACCAAACACTTGGTGTTTACGTTGTCTTTGGAGTACAAAGCCAGTAGATACTTCAAATTCATTTGAAGTTCTGACAGTAGAAGACACACAAGGAATGGACAATCTTGCTTGTGAAAGTCAACAACCCACCTCTGAAGAAGTAGTGGAAAATCCTACCATACAGAAGGAAGTCATAGAGTGTGACGTGAAAACTACCGAAGTTGTAGGCAATGTCATACTTAAACCATCAGATGAAGGTGTTAAAGTAACACAAGAGTTAGGTCATGAGGATCTTATGGCTGCTTATGTGGAAAACACAAGCATTACCATTAAGAAACCTAATGAGCTTTCACTAGCCTTAGGTTTAAAAACAATTGCCACTCATGGTATTGCTGCAATTAATAGTGTTCCTTGGAGTAAAATTTTGGCTTATGTCAAACCATTCTTAGGACAAGCAGCAATTACAACATCAAATTGCGCTAAGAGATTAGCACAACGTGTGTTTAACAATTATATGCCTTATGTGTTTACATTATTGTTCCAATTGTGTACTTTTACTAAAAGTACCAATTCTAGAATTAGAGCTTCACTACCTACAACTATTGCTAAAAATAGTGTTAAGAGTGTTGCTAAATTATGTTTGGATGCCGGCATTAATTATGTGAAGTCACCCAAATTTTCTAAATTGTTCACAATCGCTATGTGGCTATTGTTGTTAAGTATTTGCTTAGGTTCTCTAATCTGTGTAACTGCTGCTTTTGGTGTACTCTTATCTAATTTTGGTGCTCCTTCTTATTGTAATGGCGTTAGAGAATTGTATCTTAATTCGTCTAACGTTACTACTATGGATTTCTGTGAAGGTTCTTTTCCTTGCAGCATTTGTTTAAGTGGATTAGACTCCCTTGATTCTTATCCAGCTCTTGAAACCATTCAGGTGACGATTTCATCGTACAAGCTAGACTTGACAATTTTAGGTCTGGCCGCTGAGTGGGTTTTGGCATATATGTTGTTCACAAAATTCTTTTATTTATTAGGTCTTTCAGCTATAATGCAGGTGTTCTTTGGCTATTTTGCTAGTCATTTCATCAGCAATTCTTGGCTCATGTGGTTTATCATTAGTATTGTACAAATGGCACCCGTTTCTGCAATGGTTAGGATGTACATCTTCTTTGCTTCTTTCTACTACATATGGAAGAGCTATGTTCATATCATGGATGGTTGCACCTCTTCGACTTGCATGATGTGCTATAAGCGCAATCGTGCCACACGCGTTGAGTGTACAACTATTGTTAATGGCATGAAGAGATCTTTCTATGTCTATGCAAATGGAGGCCGTGGCTTCTGCAAGACTCACAATTGGAATTGTCTCAATTGTGACACATTTTGCACTGGTAGTACATTCATTAGTGATGAAGTTGCTCGTGATTTGTCACTCCAGTTTAAAAGACCAATCAACCCTACTGACCAGTCATCGTATATTGTTGATAGTGTTGCTGTGAAAAATGGCGCGCTTCACCTCTACTTTGACAAGGCTGGTCAAAAGACCTATGAGAGACATCCGCTCTCCCATTTTGTCAATTTAGACAATTTGAGAGCTAACAACACTAAAGGTTCACTGCCTATTAATGTCATAGTTTTTGATGGCAAGTCCAAATGCGACGAGTCTGCTTCTAAGTCTGCTTCTGTGTACTACAGTCAGCTGATGTGCCAACCTATTCTGTTGCTTGACCAAGCTCTTGTATCAGACGTTGGAGATAGTACTGAAGTTTCCGTTAAGATGTTTGATGCTTATGTCGACACCTTTTCAGCAACTTTTAGTGTTTCTATGGAAAAACTTAAGGCACTTGTTGCTACAGCTCACAGCGAGTTAGCAAAGGGTGTAGCTTTAGATGGTGTCCTTTCTACATTCGTGTCAGCTGCCCGACAAGGTGTTGTTGATACCGATGTTGACACAAAGGATGTTATTGAATGTCTCAAACTTTCACATCACTCTGACTTAGAAGTGACAGGTGACAGTTGTAACAATTTCATGCTCACCTATAATAAGGTTGAAAACATGACGCCCAGAGATCTTGGCGCATGTATTGACTGTAATGCAAGGCATATCAATGCCCAAGTAGCAAAAAGTCACAATGTTTCACTCATCTGGAATGTAAAAGACTACATGTCTTTATCTGAACAGCTGCGTAAACAAATTCGTAGTGCTGCCAAGAAGAACAACATACCTTTTAGACTAACTTGTGCTACAACTAGACAGGTTGTCAATGTCATAACTACTAAAATCTCACTCAAGGGTGGTAAGATTGTTAGTACTTGTTTTAAACTTATGCTTAAGGCCACATTATTGTGCGTTCTTGCTGCATTGGTTTGTTATATCGTTATGCCAGTACATACATTGTCAATCCATGATGGTTACACAAATGAAATCATTGGTTACAAAGCCATTCAGGATGGTGTCACTCGTGACATCATTTCTACTGATGATTGTTTTGCAAATAAACATGCTGGTTTTGACGCATGGTTTAGCCAGCGTGGTGGTTCATACAAAAATGACAAAAGCTGCCCTGTAGTAGCTGCTATCATTACAAGAGAGATTGGTTTCATAGTGCCTGGCTTACCGGGTACTGTGCTGAGAGCAATCAATGGTGACTTCTTGCATTTTCTACCTCGTGTTTTTAGTGCTGTTGGCAACATTTGCTACACACCTTCCAAACTCATTGAGTATAGTGATTTTGCTACCTCTGCTTGCGTTCTTGCTGCTGAGTGTACAATTTTTAAGGATGCTATGGGCAAACCTGTGCCATATTGTTATGACACTAATTTGCTAGAGGGTTCTATTTCTTATAGTGAGCTTCGTCCAGACACTCGTTATGTGCTTATGGATGGTTCCATCATACAGTTTCCTAACACTTACCTGGAGGGTTCTGTTAGAGTAGTAACAACTTTTGATGCTGAGTACTGTAGACATGGTACATGCGAAAGGTCAGAAGTAGGTATTTGCCTATCTACCAGTGGTAGATGGGTTCTTAATAATGAGCATTACAGAGCTCTATCAGGAGTTTTCTGTGGTGTTGATGCGATGAATCTCATAGCTAACATCTTTACTCCTCTTGTGCAACCTGTGGGTGCTTTAGATGTGTCTGCTTCAGTAGTGGCTGGTGGTATTATTGCCATATTGGTGACTTGTGCTGCCTACTACTTTATGAAATTCAGACGTGTTTTTGGTGAGTACAACCATGTTGTTGCTGCTAATGCACTTTTGTTTTTGATGTCTTTCACTATACTCTGTCTGGTACCAGCTTACAGCTTTCTGCCGGGAGTCTACTCAGTCTTTTACTTGTACTTGACATTCTATTTCACCAATGATGTTTCATTCTTGGCTCACCTTCAATGGTTTGCCATGTTTTCTCCTATTGTGCCTTTTTGGATAACAGCAATCTATGTATTCTGTATTTCTCTGAAGCACTGCCATTGGTTCTTTAACAACTATCTTAGGAAAAGAGTCATGTTTAATGGAGTTACATTTAGTACCTTCGAGGAGGCTGCTTTGTGTACCTTTTTGCTCAACAAGGAAATGTACCTAAAATTGCGTAGCGAGACACTGTTGCCACTTACACAGTATAACAGGTATCTTGCTCTATATAACAAGTACAAGTATTTCAGTGGAGCCTTAGATACTACCAGCTATCGTGAAGCAGCTTGCTGCCACTTAGCAAAGGCTCTAAATGACTTTAGCAACTCAGGTGCTGATGTTCTCTACCAACCACCACAGACATCAATCACTTCTGCTGTTCTGCAGAGTGGTTTTAGGAAAATGGCATTCCCGTCAGGCAAAGTTGAAGGGTGCATGGTACAAGTAACCTGTGGAACTACAACTCTTAATGGATTGTGGTTGGATGACACAGTATACTGTCCAAGACATGTCATTTGCACAGCAGAAGACATGCTTAATCCTAACTATGAAGATCTGCTCATTCGCAAATCCAACCATAGCTTTCTTGTTCAGGCTGGCAATGTTCAACTTCGTGTTATTGGCCATTCTATGCAAAATTGTCTGCTTAGGCTTAAAGTTGATACTTCTAACCCTAAGACACCCAAGTATAAATTTGTCCGTATCCAACCTGGTCAAACATTTTCAGTTCTAGCATGCTACAATGGTTCACCATCTGGTGTTTATCAGTGTGCCATGAGACCTAATCATACCATTAAAGGTTCTTTCCTTAATGGATCATGTGGTAGTGTTGGTTTTAACATTGATTATGATTGCGTGTCTTTCTGCTATATGCATCATATGGAGCTTCCAACAGGAGTACACGCTGGTACTGACTTAGAAGGTAAATTCTATGGTCCATTTGTTGACAGACAAACTGCACAGGCTGCAGGTACAGACACAACCATAACATTAAATGTTTTGGCATGGCTGTATGCTGCTGTTATCAATGGTGATAGGTGGTTTCTTAATAGATTCACCACTACTTTGAATGACTTTAACCTTGTGGCAATGAAGTACAACTATGAACCTTTGACACAAGATCATGTTGACATATTGGGACCTCTTTCTGCTCAAACAGGAATTGCCGTCTTAGATATGTGTGCTGCTTTGAAAGAGCTGCTGCAGAATGGTATGAATGGTCGTACTATCCTTGGTAGCACTATTTTAGAAGATGAGTTTACACCATTTGATGTTGTTAGACAATGCTCTGGTGTTACCTTCCAAGGTAAGTTCAAGAAAATTGTTAAGGGCACTCATCATTGGATGCTTTTAACTTTCTTGACATCACTATTGATTCTTGTTCAAAGTACACAGTGGTCACTGTTTTTCTTTGTTTACGAGAATGCTTTCTTGCCATTTACTCTTGGTATTATGGCAATTGCTGCATGTGCTATGCTGCTTGTTAAGCATAAGCACGCATTCTTGTGCTTGTTTCTGTTACCTTCTCTTGCAACAGTTGCTTACTTTAATATGGTCTACATGCCTGCTAGCTGGGTGATGCGTATCATGACATGGCTTGAATTGGCTGACACTAGCTTGTCTGGTTATAGGCTTAAGGATTGTGTTATGTATGCTTCAGCTTTAGTTTTGCTTATTCTCATGACAGCTCGCACTGTTTATGATGATGCTGCTAGACGTGTTTGGACACTGATGAATGTCATTACACTTGTTTACAAAGTCTACTATGGTAATGCTTTAGATCAAGCTATTTCCATGTGGGCCTTAGTTATTTCTGTAACCTCTAACTATTCTGGTGTCGTTACGACTATCATGTTTTTAGCTAGAGCTATAGTGTTTGTGTGTGTTGAGTATTACCCATTGTTATTTATTACTGGCAACACCTTACAGTGTATCATGCTTGTTTATTGTTTCTTAGGCTATTGTTGCTGCTGCTACTTTGGCCTTTTCTGTTTACTCAACCGTTACTTCAGGCTTACTCTTGGTGTTTATGACTACTTGGTCTCTACACAAGAATTTAGGTATATGAACTCCCAGGGGCTTTTGCCTCCTAAGAGTAGTATTGATGCTTTCAAGCTTAACATTAAGTTGTTGGGTATTGGAGGTAAACCATGTATCAAGGTTGCTACTGTACAGTCTAAAATGTCTGACGTAAAGTGCACATCTGTGGTACTGCTCTCGGTTCTTCAACAACTTAGAGTAGAGTCATCTTCTAAATTGTGGGCACAATGTGTACAACTCCACAATGATATTCTTCTTGCAAAAGACACAACTGAAGCTTTCGAGAAGATGGTTTCTCTTTTGTCTGTTTTGCTATCCATGCAGGGTGCTGTAGACATTAATAGGTTGTGCGAGGAAATGCTCGATAACCGTGCTACTCTTCAGGCTATTGCTTCAGAATTTAGTTCTTTACCATCATATGCCGCTTATGCCACTGCCCAGGAGGCCTATGAGCAGGCTGTAGCTAATGGTGATTCTGAAGTCGTTCTCAAAAAGTTAAAGAAATCTTTGAATGTGGCTAAATCTGAGTTTGACCGTGATGCTGCCATGCAACGCAAGTTGGAAAAGATGGCAGATCAGGCTATGACCCAAATGTACAAACAGGCAAGATCTGAGGACAAGAGGGCAAAAGTAACTAGTGCTATGCAAACAATGCTCTTCACTATGCTTAGGAAGCTTGATAATGATGCACTTAACAACATTATCAACAATGCGCGTGATGGTTGTGTTCCACTCAACATCATACCATTGACTACAGCAGCCAAACTCATGGTTGTTGTCCCTGATTATGGTACCTACAAGAACACTTGTGATGGTAACACCTTTACATATGCATCTGCACTCTGGGAAATCCAGCAAGTTGTTGATGCGGATAGCAAGATTGTTCAACTTAGTGAAATTAACATGGACAATTCACCAAATTTGGCTTGGCCTCTTATTGTTACAGCTCTAAGAGCCAACTCAGCTGTTAAACTACAGAATAATGAACTGAGTCCAGTAGCACTACGACAGATGTCCTGTGCGGCTGGTACCACACAAACAGCTTGTACTGATGACAATGCACTTGCCTACTATAACAATTCGAAGGGAGGTAGGTTTGTGCTGGCATTACTATCAGACCACCAAGATCTCAAATGGGCTAGATTCCCTAAGAGTGATGGTACAGGTACAATTTACACAGAACTGGAACCACCTTGTAGGTTTGTTACAGACACACCAAAAGGGCCTAAAGTGAAATACTTGTACTTCATCAAAGGCTTAAACAACCTAAATAGAGGTATGGTGCTGGGCAGTTTAGCTGCTACAGTACGTCTTCAGGCTGGAAATGCTACAGAAGTACCTGCCAATTCAACTGTGCTTTCCTTCTGTGCTTTTGCAGTAGACCCTGCTAAAGCATATAAGGATTACCTAGCAAGTGGAGGACAACCAATCACCAACTGTGTGAAGATGTTGTGTACACACACTGGTACAGGACAGGCAATTACTGTAACACCAGAAGCTAACATGGACCAAGAGTCCTTTGGTGGTGCTTCATGTTGTCTGTATTGTAGATGCCACATTGACCATCCAAATCCTAAAGGATTCTGTGACTTGAAAGGTAAGTACGTCCAAATACCTACCACTTGTGCTAATGACCCAGTGGGTTTTACACTTAGAAACACAGTCTGTACCGTCTGCGGAATGTGGAAAGGTTATGGCTGTAGTTGTGACCAACTCCGCGAACCCTTGATGCAGTCTGCGGATGCATCAACGTTTTTAAACGGGTTTGCGGTGTAA
Protein
MESLVLGVNEKTHVQLSLPVLQVRDVLVRGFGDSVEEALSEAREHLKNGTCGLVELEKGVLPQLEQPYVFIKRSDALRTNHGHKVVELVAEMDGIQYGRSGITLGVLVPHVGETPIAYRNVLLRKNGNKGAGGHSYGIDLKSYDLGDELGTDPIEDYEQNWNTKHGSGALRELTRELNGGAVTRYVDNNFCGPDGYPLDCIKDFLARAGKSMCTLSEQLDYIESKRGVYCCRDHEHEIAWFTERSDKSYEHQTPFEIKSAKKFDTFKGECPKFVFPLNSKVKVIQPRVEKKKTEGFMGRIRSVYPVASPQECNNMHLSTLMKCNHCDEVSWQTCDFLKATCEHCGTENLVIEGPTTCGYLPTNAVVKMPCPACQDPEIGPEHSVADYHNHSNIETRLRKGGRTRCFGGCVFAYVGCYNKRAYWVPRASADIGSGHTGITGDNVETLNEDLLEILSRERVNINIVGDFHLNEEVAIILASFSASTSAFIDTIKSLDYKSFKTIVESCGNYKVTKGKPVKGAWNIGQQRSVLTPLCGFPSQAAGVIRSIFARTLDAANHSIPDLQRAAVTILDGISEQSLRLVDAMVYTSDLLTNSVIIMAYVTGGLVQQTSQWLSNLLGTTVEKLRPIFEWIEAKLSAGAEFLKDAWEILKFLITGVFDIVKGQIQVASDNIKDCVKCFIDVVNKALEMCIDQVTIAGAKLRSLNLGEVFIAQSKGLYRQCIRGKEQLQLLMPLKAPKEVTFLEGDSHDTVLTSEEVVLKNGALEALETPVDSFTNGAIVGTPVCVNGLMLLEIKDKEQYCALSPGLLATNNVFRLKGGAPIKGVTFGEDTVWEVQGYKNVRITFELDERVDKVLNEKCSVYTVESGTEVTEFACVVAEAVVKTLQPVSDLLTNMGIDLDEWSVATFYLFDDAGEENFSSRMYCSFYPPDEEEEDDAECEEEEIDETCEHEYGTEDDYQGLPLEFGASAETVRVEEEEEEDWLDDTTEQSEIEPEPEPTPEEPVNQFTGYLKLTDNVAIKCVDIVKEAQSANPMVIVNAANIHLKHGGGVAGALNKATNGAMQKESDDYIKLNGPLTVGGSCLLSGHNLAKKCLHVVGPNLNAGEDIQLLKAAYENFNSQDILLAPLLSAGIFGAKPLQSLQVCVQTVRTQVYIVVNDKALYEQVVMDYLDNLKPRVEAPKQEEPPNTEDSKTEEKSVVQKPVDVKPKIKACIDEVTTTLEETKFLTNKLLLFADINGKLYHDSQNMLRGEDMSFLEKDAPYMVGDVITSGDITCVVIPSKKAGGTTEMLSRALKKVPVDEYITTYPGQGCAGYTLEEAKTALKKCKSAFYVLPSEAPNAKEEILGTVSWNLREMLAHAEETRKLMPICMDVRAIMATIQRKYKGIKIQEGIVDYGVRFFFYTSKEPVASIITKLNSLNEPLVTMPIGYVTHGFNLEEAARCMRSLKAPAVVSVSSPDAVTTYNGYLTSSSKTSEEHLVETVSWAGSYRDGSYSGQRTELGVEFLKRGDKIVYHTLESPVEFHLDGEVLSLDKLKSLLSLREVKTIKVFTTVDNTNLHTQLVDMSMTYGQQFGPTYLDGADVTKIKPHVNHEGKTFFVLPSDDTLRSEAFEYYHTLDESFLGRYMSALNHTKKWKFPQVGGLTSIKWADNNCYLSSVLLALQQLEVKFNAPALQEAYYRARAGDAANFCALILAYSNKTVGELGDVRETMTHLLQHANLESAKRVLNVVCKHCGQKTTTLTGVEAVMYMGTLSYDNLKTGVSIPCVCGRDATQYLVQQESSFVMMSAPPAEYKLQQGTFLCANEYTGNYQCGHYTHITAKETLYRIDGAHLTKMSEYKGPVTDVFYKETSYTTTIKPVSYKLDGVTYTEIEPKLDGYYKKDNAYYTEQPIDLVPTQPLPNASFDNFKLTCSNTKFADDLNQMTGFTKPASRELSVTFFPDLNGDVVAIDYRHYSASFKKGAKLLHKPIVWHINQATTKTTFKPNTWCLRCLWSTKPVDTSNSFEVLTVEDTQGMDNLACESQQPTSEEVVENPTIQKEVIECDVKTTEVVGNVILKPSDEGVKVTQELGHEDLMAAYVENTSITIKKPNELSLALGLKTIATHGIAAINSVPWSKILAYVKPFLGQAAITTSNCAKRLAQRVFNNYMPYVFTLLFQLCTFTKSTNSRIRASLPTTIAKNSVKSVAKLCLDAGINYVKSPKFSKLFTIAMWLLLLSICLGSLICVTAAFGVLLSNFGAPSYCNGVRELYLNSSNVTTMDFCEGSFPCSICLSGLDSLDSYPALETIQVTISSYKLDLTILGLAAEWVLAYMLFTKFFYLLGLSAIMQVFFGYFASHFISNSWLMWFIISIVQMAPVSAMVRMYIFFASFYYIWKSYVHIMDGCTSSTCMMCYKRNRATRVECTTIVNGMKRSFYVYANGGRGFCKTHNWNCLNCDTFCTGSTFISDEVARDLSLQFKRPINPTDQSSYIVDSVAVKNGALHLYFDKAGQKTYERHPLSHFVNLDNLRANNTKGSLPINVIVFDGKSKCDESASKSASVYYSQLMCQPILLLDQALVSDVGDSTEVSVKMFDAYVDTFSATFSVSMEKLKALVATAHSELAKGVALDGVLSTFVSAARQGVVDTDVDTKDVIECLKLSHHSDLEVTGDSCNNFMLTYNKVENMTPRDLGACIDCNARHINAQVAKSHNVSLIWNVKDYMSLSEQLRKQIRSAAKKNNIPFRLTCATTRQVVNVITTKISLKGGKIVSTCFKLMLKATLLCVLAALVCYIVMPVHTLSIHDGYTNEIIGYKAIQDGVTRDIISTDDCFANKHAGFDAWFSQRGGSYKNDKSCPVVAAIITREIGFIVPGLPGTVLRAINGDFLHFLPRVFSAVGNICYTPSKLIEYSDFATSACVLAAECTIFKDAMGKPVPYCYDTNLLEGSISYSELRPDTRYVLMDGSIIQFPNTYLEGSVRVVTTFDAEYCRHGTCERSEVGICLSTSGRWVLNNEHYRALSGVFCGVDAMNLIANIFTPLVQPVGALDVSASVVAGGIIAILVTCAAYYFMKFRRVFGEYNHVVAANALLFLMSFTILCLVPAYSFLPGVYSVFYLYLTFYFTNDVSFLAHLQWFAMFSPIVPFWITAIYVFCISLKHCHWFFNNYLRKRVMFNGVTFSTFEEAALCTFLLNKEMYLKLRSETLLPLTQYNRYLALYNKYKYFSGALDTTSYREAACCHLAKALNDFSNSGADVLYQPPQTSITSAVLQSGFRKMAFPSGKVEGCMVQVTCGTTTLNGLWLDDTVYCPRHVICTAEDMLNPNYEDLLIRKSNHSFLVQAGNVQLRVIGHSMQNCLLRLKVDTSNPKTPKYKFVRIQPGQTFSVLACYNGSPSGVYQCAMRPNHTIKGSFLNGSCGSVGFNIDYDCVSFCYMHHMELPTGVHAGTDLEGKFYGPFVDRQTAQAAGTDTTITLNVLAWLYAAVINGDRWFLNRFTTTLNDFNLVAMKYNYEPLTQDHVDILGPLSAQTGIAVLDMCAALKELLQNGMNGRTILGSTILEDEFTPFDVVRQCSGVTFQGKFKKIVKGTHHWMLLTFLTSLLILVQSTQWSLFFFVYENAFLPFTLGIMAIAACAMLLVKHKHAFLCLFLLPSLATVAYFNMVYMPASWVMRIMTWLELADTSLSGYRLKDCVMYASALVLLILMTARTVYDDAARRVWTLMNVITLVYKVYYGNALDQAISMWALVISVTSNYSGVVTTIMFLARAIVFVCVEYYPLLFITGNTLQCIMLVYCFLGYCCCCYFGLFCLLNRYFRLTLGVYDYLVSTQEFRYMNSQGLLPPKSSIDAFKLNIKLLGIGGKPCIKVATVQSKMSDVKCTSVVLLSVLQQLRVESSSKLWAQCVQLHNDILLAKDTTEAFEKMVSLLSVLLSMQGAVDINRLCEEMLDNRATLQAIASEFSSLPSYAAYATAQEAYEQAVANGDSEVVLKKLKKSLNVAKSEFDRDAAMQRKLEKMADQAMTQMYKQARSEDKRAKVTSAMQTMLFTMLRKLDNDALNNIINNARDGCVPLNIIPLTTAAKLMVVVPDYGTYKNTCDGNTFTYASALWEIQQVVDADSKIVQLSEINMDNSPNLAWPLIVTALRANSAVKLQNNELSPVALRQMSCAAGTTQTACTDDNALAYYNNSKGGRFVLALLSDHQDLKWARFPKSDGTGTIYTELEPPCRFVTDTPKGPKVKYLYFIKGLNNLNRGMVLGSLAATVRLQAGNATEVPANSTVLSFCAFAVDPAKAYKDYLASGGQPITNCVKMLCTHTGTGQAITVTPEANMDQESFGGASCCLYCRCHIDHPNPKGFCDLKGKYVQIPTTCANDPVGFTLRNTVCTVCGMWKGYGCSCDQLREPLMQSADASTFLNGFAV
Summary
Function
The main proteinase 3CL-PRO is responsible for the majority of cleavages as it cleaves the C-terminus of replicase polyprotein at 11 sites. Recognizes substrates containing the core sequence [ILMVF]-Q-|-[SGACN]. Inhibited by the substrate-analog Cbz-Val-Asn-Ser-Thr-Leu-Gln-CMK (By similarity). Also contains an ADP-ribose-1''-phosphate (ADRP)-binding function.
Catalytic Activity
Thiol-dependent hydrolysis of ester, thioester, amide, peptide and isopeptide bonds formed by the C-terminal Gly of ubiquitin (a 76-residue protein attached to proteins as an intracellular targeting signal).
TSAVLQ-|-SGFRK-NH(2) and SGVTFQ-|-GKFKK the two peptides corresponding to the two self-cleavage sites of the SARS 3C-like proteinase are the two most reactive peptide substrates. The enzyme exhibits a strong preference for substrates containing Gln at P1 position and Leu at P2 position.
TSAVLQ-|-SGFRK-NH(2) and SGVTFQ-|-GKFKK the two peptides corresponding to the two self-cleavage sites of the SARS 3C-like proteinase are the two most reactive peptide substrates. The enzyme exhibits a strong preference for substrates containing Gln at P1 position and Leu at P2 position.
Subunit
Eight copies of nsp7 and eight copies of nsp8 assemble to form a heterohexadecamer. Nsp9 is a dimer. Nsp10 forms a dodecamer.
Miscellaneous
Produced by conventional translation.
Similarity
Belongs to the coronaviruses polyprotein 1ab family.
Keywords
3D-structure
Activation of host autophagy by virus
Decay of host mRNAs by virus
Endonuclease
Eukaryotic host gene expression shutoff by virus
Eukaryotic host translation shutoff by virus
Host cytoplasm
Host gene expression shutoff by virus
Host membrane
Host mRNA suppression by virus
Host-virus interaction
Hydrolase
Inhibition of host innate immune response by virus
Inhibition of host interferon signaling pathway by virus
Inhibition of host IRF3 by virus
Inhibition of host ISG15 by virus
Inhibition of host RLR pathway by virus
Membrane
Metal-binding
Modulation of host ubiquitin pathway by viral deubiquitinase
Modulation of host ubiquitin pathway by virus
Nuclease
Protease
Reference proteome
Repeat
Ribosomal frameshifting
RNA-binding
Thiol protease
Transmembrane
Transmembrane helix
Ubl conjugation pathway
Viral immunoevasion
Zinc
Zinc-finger
Feature
chain Replicase polyprotein 1a
Uniprot
Pubmed
EMBL
AY278741
AY274119
AY278554
AY282752
AY304495
AY304486
+ More
AY304488 AY278491 AY283794 AY283795 AY283796 AY283797 AY283798 AY286320 AY278488 AY278490 AY279354 AY278489 AY291451 AY310120 AY291315 AY323977 AY321118 AY338174 AY338175 AY348314 AP006557 AP006558 AP006559 AP006560 AP006561 AY427439 AY322205 AY322206 AY463059
AY304488 AY278491 AY283794 AY283795 AY283796 AY283797 AY283798 AY286320 AY278488 AY278490 AY279354 AY278489 AY291451 AY310120 AY291315 AY323977 AY321118 AY338174 AY338175 AY348314 AP006557 AP006558 AP006559 AP006560 AP006561 AY427439 AY322205 AY322206 AY463059
Proteomes
PRIDE
Pfam
Interpro
IPR036499
NSP9_sf
IPR014829 NSP8
IPR024358 SARS-CoV_Nsp3_N
IPR014827 Viral_protease
IPR038166 Nsp3_PL2pro_sf
IPR002589 Macro_dom
IPR024375 Nsp3_coronavir
IPR038400 Nsp3_coronavir_sf
IPR042570 NAR_sf
IPR022733 Nsp3_PL2pro
IPR018995 RNA_synth_NSP10_coronavirus
IPR038083 R1a/1ab
IPR038030 NSP1_sf
IPR021590 NSP1
IPR009003 Peptidase_S1_PA
IPR014822 NSP9
IPR013016 Peptidase_C30/C16
IPR037230 NSP8_sf
IPR038123 NSP4_C_sf
IPR032592 NAR_dom
IPR014828 NSP7
IPR036333 NSP10_sf
IPR032505 Corona_NSP4_C
IPR008740 Peptidase_C30
IPR037204 NSP7_sf
IPR014829 NSP8
IPR024358 SARS-CoV_Nsp3_N
IPR014827 Viral_protease
IPR038166 Nsp3_PL2pro_sf
IPR002589 Macro_dom
IPR024375 Nsp3_coronavir
IPR038400 Nsp3_coronavir_sf
IPR042570 NAR_sf
IPR022733 Nsp3_PL2pro
IPR018995 RNA_synth_NSP10_coronavirus
IPR038083 R1a/1ab
IPR038030 NSP1_sf
IPR021590 NSP1
IPR009003 Peptidase_S1_PA
IPR014822 NSP9
IPR013016 Peptidase_C30/C16
IPR037230 NSP8_sf
IPR038123 NSP4_C_sf
IPR032592 NAR_dom
IPR014828 NSP7
IPR036333 NSP10_sf
IPR032505 Corona_NSP4_C
IPR008740 Peptidase_C30
IPR037204 NSP7_sf
SUPFAM
Gene 3D
ProteinModelPortal
PDB
5B6O
E-value=0.0 Score= 669 Identity=99.68%
Cov(Q)=7.21% Cov(P)=100.00%
3D Structure

Ontologies
GO
GO:0003968 F:RNA-directed 5'-3' RNA polymerase activity
GO:0039502 P:suppression by virus of host type I interferon-mediated signaling pathway
GO:0003723 F:RNA binding
GO:0044220 C:host cell perinuclear region of cytoplasm
GO:0039714 C:cytoplasmic viral factory
GO:0039579 P:suppression by virus of host ISG15 activity
GO:0008242 F:omega peptidase activity
GO:0039648 P:modulation by virus of host protein ubiquitination
GO:0004197 F:cysteine-type endopeptidase activity
GO:0039520 P:induction by virus of host autophagy
GO:0039595 P:induction by virus of catabolism of host mRNA
GO:0004519 F:endonuclease activity
GO:0019079 P:viral genome replication
GO:0036459 F:thiol-dependent ubiquitinyl hydrolase activity
GO:0019082 P:viral protein processing
GO:0008270 F:zinc ion binding
GO:0039548 P:suppression by virus of host IRF3 activity
GO:0016021 C:integral component of membrane
GO:0033644 C:host cell membrane
GO:0039502 P:suppression by virus of host type I interferon-mediated signaling pathway
GO:0003723 F:RNA binding
GO:0044220 C:host cell perinuclear region of cytoplasm
GO:0039714 C:cytoplasmic viral factory
GO:0039579 P:suppression by virus of host ISG15 activity
GO:0008242 F:omega peptidase activity
GO:0039648 P:modulation by virus of host protein ubiquitination
GO:0004197 F:cysteine-type endopeptidase activity
GO:0039520 P:induction by virus of host autophagy
GO:0039595 P:induction by virus of catabolism of host mRNA
GO:0004519 F:endonuclease activity
GO:0019079 P:viral genome replication
GO:0036459 F:thiol-dependent ubiquitinyl hydrolase activity
GO:0019082 P:viral protein processing
GO:0008270 F:zinc ion binding
GO:0039548 P:suppression by virus of host IRF3 activity
GO:0016021 C:integral component of membrane
GO:0033644 C:host cell membrane
Subcellular Location
From MSLVP
Capsid
From Uniprot
Host membrane
nsp7, nsp8, nsp9 and nsp10 are localized in cytoplasmic foci, largely perinuclear. Late in infection, they merge into confluent complexes (By similarity). With evidence from 23 publications.
nsp7, nsp8, nsp9 and nsp10 are localized in cytoplasmic foci, largely perinuclear. Late in infection, they merge into confluent complexes (By similarity). With evidence from 23 publications.
Topology
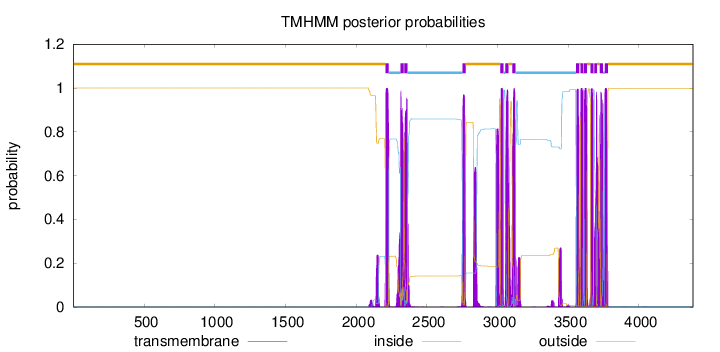
Length:
4382
Number of predicted TMHs:
14
Exp number of AAs in TMHs:
364.696289999998
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00012
outside
1 - 2208
TMhelix
2209 - 2231
inside
2232 - 2313
TMhelix
2314 - 2336
outside
2337 - 2340
TMhelix
2341 - 2363
inside
2364 - 2752
TMhelix
2753 - 2775
outside
2776 - 3019
TMhelix
3020 - 3042
inside
3043 - 3054
TMhelix
3055 - 3077
outside
3078 - 3104
TMhelix
3105 - 3127
inside
3128 - 3554
TMhelix
3555 - 3577
outside
3578 - 3586
TMhelix
3587 - 3606
inside
3607 - 3610
TMhelix
3611 - 3633
outside
3634 - 3658
TMhelix
3659 - 3678
inside
3679 - 3684
TMhelix
3685 - 3704
outside
3705 - 3723
TMhelix
3724 - 3746
inside
3747 - 3758
TMhelix
3759 - 3781
outside
3782 - 4382