Strain
Human_TGEV_KX900410
(Region: USA: Minnesota; Strain: Transmissible gastroenteritis virus strain TGEV/USA/Minnesota153/2014, complete genome.; Date: 4-Feb-14)
Gene
replicase 1b
Description
Annotated in NCBI,
replicase 1b
Location
GenBank Accession
Full name
Replicase polyprotein 1ab
Alternative Name
ORF1ab polyprotein
Sequence
CDS
TTTAAACGAGTGCGGGGTTCTAGTGCAGCTCGACTAGAACCCTGCAATGGTACTGATCCAGACCATGTTAGTAGAGCTTTTGACATCTACAACAAAGATGTTGCGTGTATTGGTAAATTTCTCAAGACGAATTGTTCAAGATTTAGGAATTTGGACAAACACGATGCCTACTACATTGTCAAACGTTGTACAAAGACCGTTATGGACCATGAGCAAGTCTGTTATAACGATCTTAAAGATTCTGGTGCTGTTGCTGAGCATGACTTCTTTACATATAAAGAGGGTAGATGTGAGTTTGGTAATGTTGCACGTAGGAATCTTACAAAGTACACAATGATGGATCTTTGTTACGCCATCAGAAATTTTGATGAAAGGAACTGTGAAGTTCTCAAAGAAATACTTGTGATAGTAGGTGCCTGCACTGAAGAATTCTTTGAAAATAAAGATTGGTTTGATCCAGTTGAAAATGAGGCCATACATGAAGTTTATGCAAAACTTGGACCCATTGTAGCCAATGCTATGCTTAAATGTGTTGCTTTTTGCGATTCGATAGTTGAAAAAGGCTATATAGGTGTTATAACACTTGACAATCAAGACCTTAATGGTAATTTCTACGATTTCGGAGATTTCGTGAAGACTGCTCCAGGTTTTGGTTGTGCTTGTGTTACATCATATTATTCTTATATGATGCCTTTAATGGGAATGACTTCATGTTTAGAGTCTGAAAACTTTGTGAAAAGTGACATCTATGGTTCTGATTATAAGCAGTATGATTTACTAGCTTATGATTTCACCGAACATAAGGAGTACCTTTTCCAAAAATACTTTAAGTACTGGGATCGCACATATCACCCAAATTGTTCTGATTGTACTAGTGACGAGTGTATCATTCATTGTGCCAATTTTAACACATTGTTTTCTATGACAATACCAATGACAGCTTTTGGACCACTTGTCCGTAAAGTTCATATTGATGGTGTACCAGTAGTTGTTACCGCAGGTTACCATTTCAAACAACTTGGTATAGTATGGAATCTTGATGTAAAATTAGACATGATGAAGTTGAGCATGACTGATCTTCTTAGATTTGTCACAGATCCAACACTTCTTGTAGCATCTAGCCCTGCACTCTTAGACCAGCGTACTGTCTGTTTCTCCATTGCAGCTTTGAGTACTGGTATTACATATCAGACAGTAAAACCAGGTCACTTTAACAAAGATTTCTACGATTTCATAACAGAGCGTGGATTCTTTGAAGAGGGATCTGAGTTAACATTAAAGCACTTTTTCTTTGCACAGGGTGGTGAAGCTGCTATGACAGACTTCAATTATTATCGCTACAATAGAGTCACAGTACTTGATATTTGCCAAGCTCAATTTGTTTACAAAATAGTTGGCAAATATTTTGAATGTTATGATGGAGGGTGCATTAGTGCTCGTGAAGTTGTTGTTACAAACTATGATAAGAGTGCTGGTTATCCTTTGAACAAATTTGGTAAAGCTAGACTTTACTACGAAACTCTTTCATATGAAGAGCAGGATGCACTTTTTGCTTTAACAAAGAGAAATGTTTTACCCACAATGACTCAAATGAATTTGAAATATGCTATTTCTGGTAAGGCAAGAGCTCGTACAGTAGGAGGAGTTTCACTTCTTTCTACCATGACTACGAGACAATACCACCAGAAGCATTTGAAGTCAATTGCTGCAACATGTAACGCTACTGTGGTTATTGGTTCAACCAAGTTTTATGGTGGTTGGGACAATATGCTTAAAAATTTAATGCGTGACGTTGATAATGGTTGTCTGATGGGATGGGACTATCCAAAGTGTGACCGTGCTCTACCTAACATGATTAGAATGGCTTCTGCCATGATATTAGGTTCTAAGCATGTTGGTTGTTGTACACATAATGATAGATTCTATCGCCTCTCCAATGAGTTAGCACAAGTACTCACAGAAGTTGTGCATTGCACAGGTGGTTTTTATTTTAAACCTGGTGGTACAACTAGTGGTGATGGTACTACAGCATATGCTAACTCTGCTTTTAACATTTTCCAAGCTGTTTCTGCTAATGTTAATAAGCTTTTAGGAGTTGATTCAAACGCTTGTAACAACGTTACAGTAAAATCCATACAGCGTAAAGTTTACGATAATTGTTATCGTAGTAGCAGCATTGACGAAGAATTTGTTGTTGAGTACTTTAGTTATTTGAGAAAACACTTTTCTATGATGATTTTATCTGATGATGGAGTCGTGTGCTACAACAAAGATTATGCTGACTTAGGTTATGTAGCTGACATTAATGCTTTTAAAGCAACACTTTATTACCAGAATAATGTCTTCATGTCCACTTCTAAGTGTTGGGTAGAACCAGATCTTAGTGTTGGACCACATGAATTTTGTTCACAGCATACATTGCAGATTGTTGGACCTGATGGAGACTACTACCTTCCCTATCCAGATCCGTCCAGAATTTTGTCAGCTGGTGTGTTTGTTGATGACATAGTTAAAACAGACAATGTTATTATGTTAGAACGTTACGTGTCATTGGCTATTGATGCATACCCGCTTACAAAACATCCTAAGCCTGCTTATCAAAAAGTTTTTTATACTCTATTAGATTGGGTTAAACATTTACAGAAAAACTTGAATGCAGGTGTTCTTGATTCTTTTTCAGTGACAATGTTAGAGGAAGGTCAAGATAAGTTCTGGAGTGAAGAGTTTTACGCTAGCCTCTATGAAAAATCTACTGTCTTGCAAGCTGCAGGTATGTGTGTAGTATGTGGTTCGCAAACTGTACTTCGTTGTGGAGACTGTCTTAGGAGACCACTTTTATGCACGAAGTGTGCTTATGACCATGTTATGGGAACAAAGCATAAATTCATTATGTCTATTACGCCATATGTGTGTAGTTTTAGTGGTTGTAATGTCAATGATGTTACAAAGTTGTTTTTAGGTGGTCTTAGTTATTATTGTATGAACCACAAACCACAGTTGTCATTCCCACTCTGTGCTAATGGCAACGTTTTTGGTCTATATAAAAGTAGTGCGGTAGGTTCAGAGGCTGTTGAAGATTTTAACAAACTTGCAGTCTCTGACTGGACTAATGTGGAAGACTACAAACTTGCTAACAATGTCAAGGAATCTCTGAAAATTTTCGCTGCTGAAACTGTGAAAGCTAAGGAGGAGTCTGTTAAATCTGAATATGCTTATGCTGTATTAAAAGAGGTTATCGGCCCTAAAGAAATTGTACTCCAATGGGAGGCTTCTAAGACTAAGCCTCCACTTAATAGAAATTCAGTTTTCACGTGTTTTCAGATAAGTAAGGATACTAAAATTCAATTAGGTGAATTTGTGTTTGAGCAATCTGAGTACGGTAGTGATTCTGTTTATTACAAGAGTACGAGTACTTATAAATTGACACCAGGTATGATTTTTGTGTTGACTTCTCACAACGTGAGTCCCCTTAAAGCTCCAATTTTAGTCAACCAAGAAAAGTACAATACCATATCTAAGCTCTATCCTGTCTTTAATATAGCGGAAGCCTATAATACACTGGTTCCTTACTACCAAATGATAGGTAAGCAAAAATTTACAACTATACAAGGTCCTCCTGGTAGCGGTAAATCTCATTGTGTTATAGGTTTGGGTTTGTATTATCCTCAGGCGAGAATAGTCTACACTGCATGTTCCCATGCTGCTGTAGACGCCTTATGTGAAAAAGCAGCCAAAAACTTCAATGTTGATAGATGTTCAAGACTAATACCTCAAAGAATCAGAGTTGACTGTTATACTGGCTTTAAGCCGAATAACACTAATGCGCAGTACTTGTTTTGTACTGTCAATGCTCTACCAGAAGTAAGTTGTGACATTGTTGTAGTTGATGAGGTCTCTATGTGCACTAATTATGATCTTAGTGTCATAAATAGCCGGTTGAGTTACAAACACATTGTCTATGTTGGAGACCCACAGCAGCTACCAGCTCCTAGAACTCTGATTAATAAAGGTGTACTTCAACCGCAGGATTACAATGTTGTAACCAAAAGAATGTGCACACTAGGACCTGATGTCTTTTTGCATAAATGTTACAGGTGCCCAGCCGAAATTGTTAAGACAGTCTCTGCACTTGTTTATGAAAACAAGTTTGTACCTGTCAACCCAGAATCAAAGCAATGCTTTAAAATGTTTGTAAAAGGCCAGGTTCAGATTGAGTCTAACTCTTCTATAAACAATAAGCAACTAGAGGTTGTCAGGGCCTTTTTAACACATAATCCAAAATGGCGCAAAGCTGTTTTCATCTCACCATATAATAGTCAAAATTATGTTGCTCGGCGCCTTCTTGGTTTGCAAACGCAAACTGTGGATTCCGCACAGGGTAGTGAGTATGATTACGTCATTTACACACAGACCTCCGATACACAGCATGCTACTAATGTTAACAGATTTAATGTTGCCATTACGAGAGCAAAGGTTGGTATACTTTGTATCATGTGTGATAGAACCATGTATGAGAATCTTGATTTCTATGAACTCAAAGATTCAAAGATTGGTTTACAAGCTAAACCTGAAACTTGTGGTTTATTTAAAGATTGTTCGAAGAGCGAACAATACATACCACCTGCTTATGCAACGACATATATGAGTTTATCTGATAATTTTAAGACAAGTGATGGTTTAGCTGTTAACATCGGTATAAAAGATGTTAAATATGCTAATGTCATCTCATATATGGGATTCAGGTTTGAAGCCAACATACCAGGTTATCATACACTATTCTGCACACGAGATTTTGCTATGCGTAATGTTAGAGCATGGCTCGGCTTTGACGTTGAAGGCGCACATGTCTGTGGTGATAATGTTGGAACTAACGTACCATTACAACTTGGTTTCTCAAACGGTGTGGATTTTGTAGTGCAAACTGAAGGGTGTGTTATTACTGAAAAAGGTAATAGCATTGAGGTTGTAAAATCACGAGCACCACCGGGTGAGCAATTTGCACACTTGATCCCGCTTATGAGAAAGGGTCAACCTTGGCACATCGTTAGACGCCGTATAGTGCAGATGGTCTGTGACTATTTTGATGGCTTATCAGACATTCTGATCTTTGTGCTTTGGGCTGGTGGTCTTGAACTTACAACTATGAGGTATTTTGTTAAAATTGGGAGACCACAAAAATGTGAGTGCGGCAAAAGTGCAACTTGTTATAGTAGCTCTCAATCCGTCTATGCTTGCTTTAAGCATGCATTGGGATGTGATTATTTATACAACCCTTATTGCATAGACATACAGCAATGGGGCTACACAGGATCTTTGAGCATGAATCATCATGAAGTTTGCAACATTCATAGAAATGAGCATGTAGCTAGTGGTGATGCTATCATGACTAGATGTCTCGCTATACATGACTGCTTTGTCAAACGTGTTGATTGGTCAATTGTGTACCCCTTTATTGACAATGAAGATAAGATCAATAAAGCTGGTCGCATAGTGCAGTCACATGTCATGAAAGCTGCTCTGAAGATTTTTAACCCTGCTGCAATTCACGATGTTGGTAATCCAAAAGGCATCCGTTGTGCTACAACACCAATACCATGGTTTTGTTATGATCGTGATCCTATTAATAATAATGTTAGATGCCTGGACTATGACTATATGGTACATGGTCAAATGAATGGTCTTATGTTATTTTGGAACTGTAATGTAGACATGTACCCAGAGTTTTCAATTGTTTGTAGATTTGACACTCGCACTCGTTCTAAATTGTCTTTAGAAGGTTGTAATGGTGGTGCATTGTATGTTAATAACCATGCTTTCCACACACCAGCTTATGATAGAAGAGCTTTTGCTAAGCTTAAACCTATGCCATTTTTCTACTATGATGATAGTAATTGTGAACTTGTTGATGGACAACCTAATTATGTACCACTTAAGTCAAATGTTTGCATAACAAAATGTAACATTGGTGGTGCTGTCTGCAAGAAGCATGCTGCTCTTTACAGAGCGTATGTTGAGGATTACAACATTTTTATGCAGGCTGGTTTTACAATATGGTGTCCTCAAACTTTTGACACTTATATGCTTTGGCATGGTTTTGTTAATAGCAGAGCACTTCAGAGTTTAGAAAATGTGGCTTTTAACGTCGTTAAGAAAGGTGCCTTCACTGGTTTAAAAGGTGACTTACCAACTGCTGTTATTGCTGACAAAATAATGGTAAGAGATGGACCTACTGACAGATGTATTTTTACAAATAAGACTAGTTTACCTACTAATGTAGCTTTTGAGTTGTATGCAAAACGCAAACTTGGACTCACACCTCCATTAACAATACTTAGGAACTTAGGTGTTGTCGCAACATATAATTTTGTGTTGTGGGATTATGAAGCTGAATGTCCTTTCTCAAATTTCACTAAGCAAGTTTGTTCTTACACTGATCTTGATAGTGAAGTTGTAACATGTTTTGATAATAGTATTGCTGGTTCTTTTGAGCGTTTTACTACTACAAGAGATGCAGTGCTTATTTCTAATAACGCTGTGAAAGGGCTTAGTGCCATTAAGTTACAATATGGCTTTTTGAATGATTTACCTGTAAGTACTATTGGGAATAAACCTGTCACATGGTATATGTATGTGCGCAAGAATGGTGAGTACGTCGAACAAATCGATAGTTATTATACACAGGGACGTACTTTTGAAACCTTTAAACCTCGTAGTACAATGGAAGAAGATTTTCTTAGTATGGATACTACACTCTTCATTCAAAAGTATGGTCTTGAGGATTATGGTTTTGAACACGTTGTATTTGGAGATGTTTCTAAAACTACCATTGGTGGTATGCATCTTCTTATATCGCAAGTGCGCCTTGCGAAAATGGGTTTGTTTTCCGTTCAAGAATTTATGAATAATTCTGACAGTACACTAAAAAGTTGTTGTATTACATATGCTGATGATCCATCTTCTAAGAATGTGTGCACTTATATGGACATACTCTTGGACGATTTTGTGACTATCATTAAGAGCTTAGATCTTAATGTTGTGTCCAAAGTTGTGGATGTCATTGTAGATTGTAAGGCATGGAGATGGATGTTGTGGTGTGAGAATTCACATATTAAAACATTCTATCCACAACTCCAATCTTCTGAATGGAATCCAGGCTATAGCATGCCTACACTGTACAAAATCCAGCGTATGTGTCTCGAACGGTGTAATCTCTACAATTATGGTGCACAAGTGAAATTACCTGACGGCATTACCACTAATGTCGTTAAGTATACTCAGTTGTGTCAATATCTTAACACTACTACATTGTGTGTACCACACAAAATGCGTGTATTGCATTTAGGAGCTGCTGGTGCATATGGTGTTGCTCCTGGTAGTACTGTATTAAGAAGATGGTTACCAGATGATGCCATATTGGTTGATAATGATTTGAGAGATTACGTTTCCGACGCTGACTTCAGTGTTACAGGTGATTGTACTAGTCTTTACATTGAAGACAAGTTTGATTTGCTCGTCTCTGATTTATACGATGGCTCCACAAAATCAATTGACGGTGAAAACACGTCGAAAGATGGTTTCTTTACTTATATTAATGGTTTCATTAAAGAGAAACTGTCACTTGGTGGATCTGTTGCCATTAAAATCACGGAATTTAGTTGGAATAAAGATTTATATGAATTGATTCAAAGATTTGAGTATTGGACTGTGTTTTGTACAAGTGTTAACACGTCATCATCAGAAGGCTTTCTGATTGGTATTAACTACTTAGGACCATACTGTGACAGAGCAATAGTAGATGGAAATATAATGCATGCCAATTATATATTTTGGAGAAATTCTACAATTATGGCTCTATCACATAACTCAGTCCTAGATACTCCTAAATTCAAGTGTCGTTGTAACAACGCACTTATTGTTAACTTAAAAGAAAAAGAATTGAATGAAATGGTCATTGGATTACTAAGGAAGGGTAAGTTGCTCATTAGAAATAATGGTAAGTTACTAAACTTTGGTAACCACTTCGTTAATACACCATGA
Protein
FKRVRGSSAARLEPCNGTDPDHVSRAFDIYNKDVACIGKFLKTNCSRFRNLDKHDAYYIVKRCTKTVMDHEQVCYNDLKDSGAVAEHDFFTYKEGRCEFGNVARRNLTKYTMMDLCYAIRNFDERNCEVLKEILVIVGACTEEFFENKDWFDPVENEAIHEVYAKLGPIVANAMLKCVAFCDSIVEKGYIGVITLDNQDLNGNFYDFGDFVKTAPGFGCACVTSYYSYMMPLMGMTSCLESENFVKSDIYGSDYKQYDLLAYDFTEHKEYLFQKYFKYWDRTYHPNCSDCTSDECIIHCANFNTLFSMTIPMTAFGPLVRKVHIDGVPVVVTAGYHFKQLGIVWNLDVKLDMMKLSMTDLLRFVTDPTLLVASSPALLDQRTVCFSIAALSTGITYQTVKPGHFNKDFYDFITERGFFEEGSELTLKHFFFAQGGEAAMTDFNYYRYNRVTVLDICQAQFVYKIVGKYFECYDGGCISAREVVVTNYDKSAGYPLNKFGKARLYYETLSYEEQDALFALTKRNVLPTMTQMNLKYAISGKARARTVGGVSLLSTMTTRQYHQKHLKSIAATCNATVVIGSTKFYGGWDNMLKNLMRDVDNGCLMGWDYPKCDRALPNMIRMASAMILGSKHVGCCTHNDRFYRLSNELAQVLTEVVHCTGGFYFKPGGTTSGDGTTAYANSAFNIFQAVSANVNKLLGVDSNACNNVTVKSIQRKVYDNCYRSSSIDEEFVVEYFSYLRKHFSMMILSDDGVVCYNKDYADLGYVADINAFKATLYYQNNVFMSTSKCWVEPDLSVGPHEFCSQHTLQIVGPDGDYYLPYPDPSRILSAGVFVDDIVKTDNVIMLERYVSLAIDAYPLTKHPKPAYQKVFYTLLDWVKHLQKNLNAGVLDSFSVTMLEEGQDKFWSEEFYASLYEKSTVLQAAGMCVVCGSQTVLRCGDCLRRPLLCTKCAYDHVMGTKHKFIMSITPYVCSFSGCNVNDVTKLFLGGLSYYCMNHKPQLSFPLCANGNVFGLYKSSAVGSEAVEDFNKLAVSDWTNVEDYKLANNVKESLKIFAAETVKAKEESVKSEYAYAVLKEVIGPKEIVLQWEASKTKPPLNRNSVFTCFQISKDTKIQLGEFVFEQSEYGSDSVYYKSTSTYKLTPGMIFVLTSHNVSPLKAPILVNQEKYNTISKLYPVFNIAEAYNTLVPYYQMIGKQKFTTIQGPPGSGKSHCVIGLGLYYPQARIVYTACSHAAVDALCEKAAKNFNVDRCSRLIPQRIRVDCYTGFKPNNTNAQYLFCTVNALPEVSCDIVVVDEVSMCTNYDLSVINSRLSYKHIVYVGDPQQLPAPRTLINKGVLQPQDYNVVTKRMCTLGPDVFLHKCYRCPAEIVKTVSALVYENKFVPVNPESKQCFKMFVKGQVQIESNSSINNKQLEVVRAFLTHNPKWRKAVFISPYNSQNYVARRLLGLQTQTVDSAQGSEYDYVIYTQTSDTQHATNVNRFNVAITRAKVGILCIMCDRTMYENLDFYELKDSKIGLQAKPETCGLFKDCSKSEQYIPPAYATTYMSLSDNFKTSDGLAVNIGIKDVKYANVISYMGFRFEANIPGYHTLFCTRDFAMRNVRAWLGFDVEGAHVCGDNVGTNVPLQLGFSNGVDFVVQTEGCVITEKGNSIEVVKSRAPPGEQFAHLIPLMRKGQPWHIVRRRIVQMVCDYFDGLSDILIFVLWAGGLELTTMRYFVKIGRPQKCECGKSATCYSSSQSVYACFKHALGCDYLYNPYCIDIQQWGYTGSLSMNHHEVCNIHRNEHVASGDAIMTRCLAIHDCFVKRVDWSIVYPFIDNEDKINKAGRIVQSHVMKAALKIFNPAAIHDVGNPKGIRCATTPIPWFCYDRDPINNNVRCLDYDYMVHGQMNGLMLFWNCNVDMYPEFSIVCRFDTRTRSKLSLEGCNGGALYVNNHAFHTPAYDRRAFAKLKPMPFFYYDDSNCELVDGQPNYVPLKSNVCITKCNIGGAVCKKHAALYRAYVEDYNIFMQAGFTIWCPQTFDTYMLWHGFVNSRALQSLENVAFNVVKKGAFTGLKGDLPTAVIADKIMVRDGPTDRCIFTNKTSLPTNVAFELYAKRKLGLTPPLTILRNLGVVATYNFVLWDYEAECPFSNFTKQVCSYTDLDSEVVTCFDNSIAGSFERFTTTRDAVLISNNAVKGLSAIKLQYGFLNDLPVSTIGNKPVTWYMYVRKNGEYVEQIDSYYTQGRTFETFKPRSTMEEDFLSMDTTLFIQKYGLEDYGFEHVVFGDVSKTTIGGMHLLISQVRLAKMGLFSVQEFMNNSDSTLKSCCITYADDPSSKNVCTYMDILLDDFVTIIKSLDLNVVSKVVDVIVDCKAWRWMLWCENSHIKTFYPQLQSSEWNPGYSMPTLYKIQRMCLERCNLYNYGAQVKLPDGITTNVVKYTQLCQYLNTTTLCVPHKMRVLHLGAAGAYGVAPGSTVLRRWLPDDAILVDNDLRDYVSDADFSVTGDCTSLYIEDKFDLLVSDLYDGSTKSIDGENTSKDGFFTYINGFIKEKLSLGGSVAIKITEFSWNKDLYELIQRFEYWTVFCTSVNTSSSEGFLIGINYLGPYCDRAIVDGNIMHANYIFWRNSTIMALSHNSVLDTPKFKCRCNNALIVNLKEKELNEMVIGLLRKGKLLIRNNGKLLNFGNHFVNTP
Summary
Function
The replicase polyprotein of coronaviruses is a multifunctional protein: it contains the activities necessary for the transcription of negative stranded RNA, leader RNA, subgenomic mRNAs and progeny virion RNA as well as proteinases responsible for the cleavage of the polyprotein into functional products.
Non-structural protein 1 inhibits host translation. By suppressing host gene expression, nsp1 facilitates efficient viral gene expression in infected cells and evasion from host immune response.
The papain-like proteinase 1 (PLP1) and papain-like proteinase 2 (PLP2) are responsible for the cleavages located at the N-terminus of the replicase polyprotein. In addition, PLP2 possesses a deubiquitinating/deISGylating activity and processes both 'Lys-48'- and 'Lys-63'-linked polyubiquitin chains from cellular substrates. PLP2 also antagonizes innate immune induction of type I interferon by blocking the nuclear translocation of host IRF-3 (By similarity).
The main proteinase 3CL-PRO is responsible for the majority of cleavages as it cleaves the C-terminus of replicase polyprotein at 11 sites. Recognizes substrates containing the core sequence [ILMVF]-Q-|-[SAGC]. Inhibited by the substrate-analog Cbz-Val-Asn-Ser-Thr-Leu-Gln-CMK.
The helicase which contains a zinc finger structure displays RNA and DNA duplex-unwinding activities with 5' to 3' polarity. ATPase activity is strongly stimulated by poly(U), poly(dT), poly(C), poly(dA), but not by poly(G).
The exoribonuclease acts on both ssRNA and dsRNA in a 3' to 5' direction.
Nsp7-nsp8 hexadecamer may possibly confer processivity to the polymerase, maybe by binding to dsRNA or by producing primers utilized by the latter.
Nsp9 is a ssRNA-binding protein.
NendoU is a Mn(2+)-dependent, uridylate-specific enzyme, which leaves 2'-3'-cyclic phosphates 5' to the cleaved bond.
Non-structural protein 1 inhibits host translation. By suppressing host gene expression, nsp1 facilitates efficient viral gene expression in infected cells and evasion from host immune response.
The papain-like proteinase 1 (PLP1) and papain-like proteinase 2 (PLP2) are responsible for the cleavages located at the N-terminus of the replicase polyprotein. In addition, PLP2 possesses a deubiquitinating/deISGylating activity and processes both 'Lys-48'- and 'Lys-63'-linked polyubiquitin chains from cellular substrates. PLP2 also antagonizes innate immune induction of type I interferon by blocking the nuclear translocation of host IRF-3 (By similarity).
The main proteinase 3CL-PRO is responsible for the majority of cleavages as it cleaves the C-terminus of replicase polyprotein at 11 sites. Recognizes substrates containing the core sequence [ILMVF]-Q-|-[SAGC]. Inhibited by the substrate-analog Cbz-Val-Asn-Ser-Thr-Leu-Gln-CMK.
The helicase which contains a zinc finger structure displays RNA and DNA duplex-unwinding activities with 5' to 3' polarity. ATPase activity is strongly stimulated by poly(U), poly(dT), poly(C), poly(dA), but not by poly(G).
The exoribonuclease acts on both ssRNA and dsRNA in a 3' to 5' direction.
Nsp7-nsp8 hexadecamer may possibly confer processivity to the polymerase, maybe by binding to dsRNA or by producing primers utilized by the latter.
Nsp9 is a ssRNA-binding protein.
NendoU is a Mn(2+)-dependent, uridylate-specific enzyme, which leaves 2'-3'-cyclic phosphates 5' to the cleaved bond.
Catalytic Activity
Thiol-dependent hydrolysis of ester, thioester, amide, peptide and isopeptide bonds formed by the C-terminal Gly of ubiquitin (a 76-residue protein attached to proteins as an intracellular targeting signal).
a ribonucleoside 5'-triphosphate + RNA(n) = diphosphate + RNA(n+1)
ATP + H2O = ADP + H(+) + phosphate
a ribonucleoside 5'-triphosphate + RNA(n) = diphosphate + RNA(n+1)
ATP + H2O = ADP + H(+) + phosphate
Subunit
3CL-PRO exists as monomer and homodimer. Eight copies of nsp7 and eight copies of nsp8 assemble to form a heterohexadecamer. Nsp9 is a dimer. Nsp10 forms a dodecamer (By similarity).
Miscellaneous
Produced by -1 ribosomal frameshifting at the 1a-1b genes boundary.
Similarity
Belongs to the coronaviruses polyprotein 1ab family.
Keywords
3D-structure
Activation of host autophagy by virus
ATP-binding
Endonuclease
Exonuclease
Helicase
Host cytoplasm
Host membrane
Host-virus interaction
Hydrolase
Inhibition of host innate immune response by virus
Inhibition of host IRF3 by virus
Inhibition of host RLR pathway by virus
Membrane
Metal-binding
Methyltransferase
Modulation of host ubiquitin pathway by viral deubiquitinase
Modulation of host ubiquitin pathway by virus
Nuclease
Nucleotide-binding
Nucleotidyltransferase
Protease
Reference proteome
Repeat
Ribosomal frameshifting
RNA-binding
RNA-directed RNA polymerase
Thiol protease
Transferase
Transmembrane
Transmembrane helix
Ubl conjugation pathway
Viral immunoevasion
Viral RNA replication
Zinc
Zinc-finger
Feature
chain Non-structural protein 1
Uniprot
Proteomes
PRIDE
Pfam
Interpro
IPR041679
DNA2/NAM7-like_AAA
IPR036499 NSP9_sf
IPR018995 RNA_synth_NSP10_coronavirus
IPR027351 (+)RNA_virus_helicase_core_dom
IPR029063 SAM-dependent_MTases
IPR038634 A-CoV_nsp1_sf
IPR042515 Nsp15_N
IPR038123 NSP4_C_sf
IPR037230 NSP8_sf
IPR027417 P-loop_NTPase
IPR002589 Macro_dom
IPR009461 Coronavirus_NSP16
IPR014827 Viral_protease
IPR013016 Peptidase_C30/C16
IPR014822 NSP9
IPR009003 Peptidase_S1_PA
IPR014829 NSP8
IPR037227 EndoU-like
IPR036333 NSP10_sf
IPR027352 CV_ZBD
IPR014828 NSP7
IPR032039 A-CoV_nsp1
IPR008740 Peptidase_C30
IPR037204 NSP7_sf
IPR009466 NSP11
IPR032505 Corona_NSP4_C
IPR009469 RNA_pol_N_coronovir
IPR036499 NSP9_sf
IPR018995 RNA_synth_NSP10_coronavirus
IPR027351 (+)RNA_virus_helicase_core_dom
IPR029063 SAM-dependent_MTases
IPR038634 A-CoV_nsp1_sf
IPR042515 Nsp15_N
IPR038123 NSP4_C_sf
IPR037230 NSP8_sf
IPR027417 P-loop_NTPase
IPR002589 Macro_dom
IPR009461 Coronavirus_NSP16
IPR014827 Viral_protease
IPR013016 Peptidase_C30/C16
IPR014822 NSP9
IPR009003 Peptidase_S1_PA
IPR014829 NSP8
IPR037227 EndoU-like
IPR036333 NSP10_sf
IPR027352 CV_ZBD
IPR014828 NSP7
IPR032039 A-CoV_nsp1
IPR008740 Peptidase_C30
IPR037204 NSP7_sf
IPR009466 NSP11
IPR032505 Corona_NSP4_C
IPR009469 RNA_pol_N_coronovir
SUPFAM
ProteinModelPortal
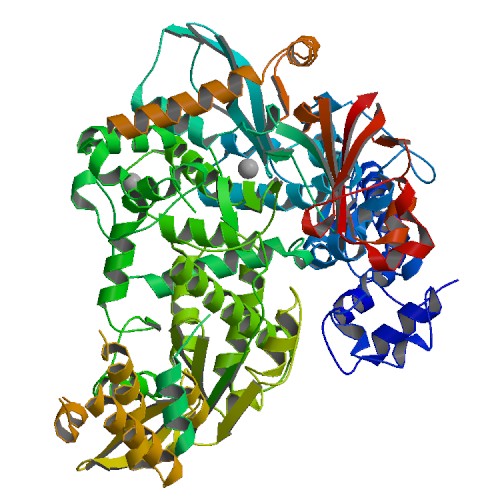
PDB
6NUS
E-value=0.0 Score=1109 Identity=58.59%
Cov(Q)=34.54% Cov(P)=96.86%
3D Structure
Ontologies
GO
GO:0036459 F:thiol-dependent ubiquitinyl hydrolase activity
GO:0032259 P:methylation
GO:0003678 F:DNA helicase activity
GO:0003968 F:RNA-directed 5'-3' RNA polymerase activity
GO:0016021 C:integral component of membrane
GO:0008242 F:omega peptidase activity
GO:0044220 C:host cell perinuclear region of cytoplasm
GO:0016896 F:exoribonuclease activity, producing 5'-phosphomonoesters
GO:0003723 F:RNA binding
GO:0039548 P:suppression by virus of host IRF3 activity
GO:0006351 P:transcription, DNA-templated
GO:0008270 F:zinc ion binding
GO:0019082 P:viral protein processing
GO:0005524 F:ATP binding
GO:0039520 P:induction by virus of host autophagy
GO:0003724 F:RNA helicase activity
GO:0044172 C:host cell endoplasmic reticulum-Golgi intermediate compartment
GO:0004197 F:cysteine-type endopeptidase activity
GO:0039648 P:modulation by virus of host protein ubiquitination
GO:0008168 F:methyltransferase activity
GO:0019079 P:viral genome replication
GO:0004519 F:endonuclease activity
GO:0033644 C:host cell membrane
GO:0032259 P:methylation
GO:0003678 F:DNA helicase activity
GO:0003968 F:RNA-directed 5'-3' RNA polymerase activity
GO:0016021 C:integral component of membrane
GO:0008242 F:omega peptidase activity
GO:0044220 C:host cell perinuclear region of cytoplasm
GO:0016896 F:exoribonuclease activity, producing 5'-phosphomonoesters
GO:0003723 F:RNA binding
GO:0039548 P:suppression by virus of host IRF3 activity
GO:0006351 P:transcription, DNA-templated
GO:0008270 F:zinc ion binding
GO:0019082 P:viral protein processing
GO:0005524 F:ATP binding
GO:0039520 P:induction by virus of host autophagy
GO:0003724 F:RNA helicase activity
GO:0044172 C:host cell endoplasmic reticulum-Golgi intermediate compartment
GO:0004197 F:cysteine-type endopeptidase activity
GO:0039648 P:modulation by virus of host protein ubiquitination
GO:0008168 F:methyltransferase activity
GO:0019079 P:viral genome replication
GO:0004519 F:endonuclease activity
GO:0033644 C:host cell membrane
Subcellular Location
From MSLVP
Capsid
From Uniprot
Host membrane
nsp7, nsp8, nsp9 and nsp10 are localized in cytoplasmic foci, largely perinuclear. Late in infection, they merge into confluent complexes (By similarity). With evidence from 3 publications.
Host endoplasmic reticulum-Golgi intermediate compartment The helicase interacts with the N protein in membranous complexes and colocalizes with sites of synthesis of new viral RNA. With evidence from 3 publications.
nsp7, nsp8, nsp9 and nsp10 are localized in cytoplasmic foci, largely perinuclear. Late in infection, they merge into confluent complexes (By similarity). With evidence from 3 publications.
Host endoplasmic reticulum-Golgi intermediate compartment The helicase interacts with the N protein in membranous complexes and colocalizes with sites of synthesis of new viral RNA. With evidence from 3 publications.
Topology
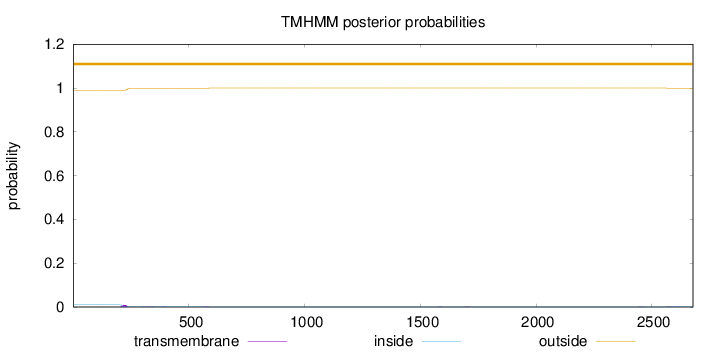
Length:
2678
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.290510000000001
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00998
outside
1 - 2678