Strain
Ferret_LC215871
(Region: Japan; Strain: Ferret coronavirus genomic RNA, complete genome, strain: ferret063.; Date: 2016/6/29)
Gene
spike protein
Description
Annotated in NCBI,
spike protein
Location
GenBank Accession
Full name
Spike glycoprotein
Alternative Name
E2
Peplomer protein
Peplomer protein
Sequence
CDS
ATGATTGGGACAACATTGTTGTTACTTTCGTGTGTTAGTTTTGTTATAACACACGAAAACCACAATTTTAACTTTTCGCAATGTGAAAGGGGCTCTTTCATAAACACGACGTTGGGAGATCATTATTATCTCTTAGATAATTTTATTAAAGATTACAGTAAGCGTTTACCAACAGGTTCCCAGGTAGTGTTAGGAGATTATTTTCCCACAGTGCAACCATGGTATAATTGTTTGTTTGATAGAAGTGTAAACGGCACAATGCTGTCCTTGCGTGACATTAAAGCTCTATATTGGGACACTAAGAAGATTAGGAATGAAGATGACGGATTATCAAATTGTTTTGTGGTACATCTTTACGGCAAACCGTACACTGTAACTGTTAAAATATCAGCTCATCACATTGCAGCGAAAGATCGTAATGTTATGTGCATTTGTGAAGGGAAGCACGAACCGTATAGGTATGATTGTTTAACTGAAGGCAGAGACTGTGGTGCAGGCTGCATAGCGCATACTTTCACAACCTGTGCCAATCTTAGCATCTGTGGTGATACCCTTTTTGGTTTGCGCTGGTCAAATTCCGAATTGGCAGCATATTTATCTGGCAACGTGTATCGCTTTAGATTAGACAACTATTGGTACAATTTTGCCACCATATCAGATCCTGATCCCTATAAAGGTGATCATAGTTGGTGGTTTAACCCTGTGCAAAGTTTCACCTATTACAATGTTAGCAAACTTAGTAATGGTACTGTTGTCTGGTCTAATTGCACCCATAATTGTGCAGATTATGTGACCAACGTGTTTGCCGTTGAGAATGGCGGGCTCATACCACCAGATTTTAGTTTTAACAATTGGTTTGTTTTAACAAACACTTCGACAGTTACCAGTGGCAAGTTTGTTTCGAGTCAGCCTCTACTTGTTAATTGTTTAACACCAGTGCCTAGCTTTGGAGAAGAAGCTTTGACAATTGACTTTGAAAAAATCCCTAGCCAGTGTAATGGTGCTACTGTTAACAGTAGTTTCGACGTTGTTAGATTCAACCTTAATGTAACTGACAATGTGGTTTCATCGAGTGGTTACAACTTTATCACACTCAATGTCACAGGTGGTGTTGAGCTGTACTTTTCTTGTTTTAATGAGTCTCAAACCGGGCCCCAATTATATGGAGGCCATTTACCTCTTGGTGTGCATGAAGGACCACTCTATTGCTATGTCATGTATAATGCCACATTGTCTAAGTTTGTTGGTGTATTACCTCCTAATGTAAAGGAAATTGCTATTAGTAAGTGGGGTGGTGTCTATATTAATGGTTTTAACTATTTTCAGACATTCCCACTATCTAGCTTTTCTTTCAATCTAACGACTGGTAATAGTGGTGCATTTTGGACTGTGGCTTATACAACATTTACAGATGTATTGTTAGATGTTGCAGACACACAAATCAAGAGTGTCGTGTATTGTAATAGTTATGTTAATGATATTAGATGTTCACAGTTGTCTACCGACCTACCGGATGGGTTCTACCCTGTGTCCTCCTTAAACCTGCCCAATGCTAATTTGAGTTTTGTAACATTGCCAGCTAATTTTGATCATAGTTATATTAATGTTACAGGTAATGTAAAAGTGGCTGTTTATGGCAAGCTTCAAGTTTTGTCTCACAGTAGCAATGTAACTCTCTACTCTGGTACTGTAGAGTCTTTGTGTGTAAACACATCACAGTTTACACTTAATTTTAACTCACATTGCAGCGTTGACTATGGTACTGAATGTACAGGCGCAGCTAGGACAGAAGTTGTAGTTGGTCCGGGTAGTTGTCCTTTTTCATTCGATAAGTTGAATAAGCACATGACTTTTGAAAAATTGTGCCTTTCAACGGTACCGTTGGATGATGACTGTAAGTTTGATCTAATAGCGAGAACAATGTTAGGTGATTTTGTGTTTGCACACTTGTATGTTGGTTACAAGTTTGGTCTGGACATCACTGGTTTAGAAGCTCCAAACCCAGGTGTTAAAGACCTATCCAACTTGCACCTAAATGTGTGTACTGAGTACAACATTTATGGACATGTTGGATTTGGCATTATAAGACAAACTAATGAGACACTCTTTGGAGGTCTGTATTATACTTCATTGTCAGGGGATCTTTTAGGTTTTAAAAATGTGACAACTGGTGTTGTGTTTTCCATAACACCTTGTGAAGTCAGTGCACAAGCGGCAGTTATAGGCGGTAAGATAGTAGGTGCTATTACGTCTGTTGATTCTGACATGTTAAACCTACCACACTACATCGAAACACCGTCGTTTTACTACCGCTCTATTTATAATTATAGTGCTATGACTTATGCGACATCAGGTATGCAAAAATATCTTGTTAATTGCACACCAGTTATCACATACTCTAATATGGGCGTGTGTGAAAATGGTGCTCTGGTATTTGTCAATATTACACAAAGTAATAGTGTTGCACAACCTATAAGCACTGGTAACATTACAATCCCTAGTAATTTTACAATTTCAGTGCAGGTTGAGTACCTTCAAATGTCTTCTGAGTTAGTCTCAATCGACTGTGCTCGGTACGTTTGTAACGGCAATGCCAGGTGCAACAAGTTGCTCACGCAGTACATGAGCGCATGTCACACTATAGAACAAGCATTGCAAACGGGTGTTAGGTTAGAGTCTCTAGAATTAGAGTCTATGATCTCTATATCTGATTCAGCTCTTGCTATTGCATCTGTTGAACAATTTAACAGTTCTCAGCACTTGAACCCTGTGTATAGTGAAGGTAACAACACTATTGGTGGAATTTATATGGATGGTTTAATGAATATACTTCCTAAAAAGGGTTGCTCTAACAAACATGGTTCCTGTCGTTCCGCTATAGAGGATCTGTTATTTAACAAGGTTGTAACGTCAGGACTTGGCACTGTTGATGAGGACTATAAGCGTTGTACCAAAGGTTTGGACATAGCAGACTTGGTGTGCGCTCAATACCATAATGGCATTATGGTGCTACCCGGTGTCGTCAATAGTGACAAGATGGCTATGTACACAGCATCCCTCGCAGGTGGTATAACTTTAGGAGCTTTAGGTGGTGGTCTTGTAGCTGTACCTTTTGCCACTGCCGTTCAAGCACGCCTAAATTATGTTGCTCTCCAGACAGATGTTTTACAGAATAATCAGAAAATGTTAGCAGCCTCCTTTAACCAGGCTATTGGTAACATCACACAGGCTTTTGGTAAAGTCAACAGTGCCATTCAGCAAACTGCTAAGGGACTGTCAACTGTAGCACAAGCCCTCACAAAAGTTCAAGATGTTGTCAATAGTCATGGCAAGGCGTTGAACCAACTCACTGCACAACTGCAAAACAATTTTCAGGCTGTTAGCAGTTCTATAGCTGATATTTATTATAGATTGGATGAGCTTCATGCTGACGCTCAAGTTGATCGTCTTATAACAGGTAGGTTGGCAGCACTTAATGCCTTTGTCACTCAAACATTGACCAGAATGACACAGGTTCGTGCTAGCAGACAGCTGGCTAAAGAAAAGATCAATGAGTGTGTGCGTTCACAGTCTAGCAGGTTTGGTTTCTGTGGCAACGGCACTCACTTGTTCTCTTTAGCTAATGCAGCACCTAGTGGTATCATGCTATTTCACACAGTTCTAGTGCCTACGTCTTACACAAGTGTAACAGCGTGGTCTGGCATTTGTTTTGAGAACGTTGGTTTGATTGTCAGGGATGTTTCGTTGACGCTGTTTAAAAATCATGATGGTAAATTCTACTTGACACCACGTACTATGTATGAACCGCGTGTCGCGACTAGCGCAGACTTCGTGCGAATTAATAGCTGTGCCACTACTTTTGTTAATGCCACTGCTACAGAGCTACCTAATATTATACCTGATTATATTGATGTTAATAAGACAGTCCAAGACATGCTAGAGCAGTATAAGCCCAATTGGACAGTACCAAATTTACACCTCGACTTGTTCAACCTAACTTACTTAAATCTCACGGGTGAGATTAATGATTTGGAGAACAGGTCTGTCACTTTGCAACAAACTGTTGCCGACTTACAGGTTTTAATTGATAATATTAATGGAACACTTGTAAATCTTGAGTGGCTTAACAGAGTTGAAACTTATGTTAAGTGGCCCTGGTGGGTTTGGGTTATTATTGGGTTAATATTGCTCATAGCACTACCTATTTTGTTGTTCTGTTGTTTATCAACAGGTTGTTGTGGCTGTTGTGGCTGCTTAACCAGCTGCTTAGCCGGTTGTTGTAAAAATAGTTGTAAAAAGCCCTCTTATTATGAGCCTATGGAGAAGGTTCATATTAATTAA
Protein
MIGTTLLLLSCVSFVITHENHNFNFSQCERGSFINTTLGDHYYLLDNFIKDYSKRLPTGSQVVLGDYFPTVQPWYNCLFDRSVNGTMLSLRDIKALYWDTKKIRNEDDGLSNCFVVHLYGKPYTVTVKISAHHIAAKDRNVMCICEGKHEPYRYDCLTEGRDCGAGCIAHTFTTCANLSICGDTLFGLRWSNSELAAYLSGNVYRFRLDNYWYNFATISDPDPYKGDHSWWFNPVQSFTYYNVSKLSNGTVVWSNCTHNCADYVTNVFAVENGGLIPPDFSFNNWFVLTNTSTVTSGKFVSSQPLLVNCLTPVPSFGEEALTIDFEKIPSQCNGATVNSSFDVVRFNLNVTDNVVSSSGYNFITLNVTGGVELYFSCFNESQTGPQLYGGHLPLGVHEGPLYCYVMYNATLSKFVGVLPPNVKEIAISKWGGVYINGFNYFQTFPLSSFSFNLTTGNSGAFWTVAYTTFTDVLLDVADTQIKSVVYCNSYVNDIRCSQLSTDLPDGFYPVSSLNLPNANLSFVTLPANFDHSYINVTGNVKVAVYGKLQVLSHSSNVTLYSGTVESLCVNTSQFTLNFNSHCSVDYGTECTGAARTEVVVGPGSCPFSFDKLNKHMTFEKLCLSTVPLDDDCKFDLIARTMLGDFVFAHLYVGYKFGLDITGLEAPNPGVKDLSNLHLNVCTEYNIYGHVGFGIIRQTNETLFGGLYYTSLSGDLLGFKNVTTGVVFSITPCEVSAQAAVIGGKIVGAITSVDSDMLNLPHYIETPSFYYRSIYNYSAMTYATSGMQKYLVNCTPVITYSNMGVCENGALVFVNITQSNSVAQPISTGNITIPSNFTISVQVEYLQMSSELVSIDCARYVCNGNARCNKLLTQYMSACHTIEQALQTGVRLESLELESMISISDSALAIASVEQFNSSQHLNPVYSEGNNTIGGIYMDGLMNILPKKGCSNKHGSCRSAIEDLLFNKVVTSGLGTVDEDYKRCTKGLDIADLVCAQYHNGIMVLPGVVNSDKMAMYTASLAGGITLGALGGGLVAVPFATAVQARLNYVALQTDVLQNNQKMLAASFNQAIGNITQAFGKVNSAIQQTAKGLSTVAQALTKVQDVVNSHGKALNQLTAQLQNNFQAVSSSIADIYYRLDELHADAQVDRLITGRLAALNAFVTQTLTRMTQVRASRQLAKEKINECVRSQSSRFGFCGNGTHLFSLANAAPSGIMLFHTVLVPTSYTSVTAWSGICFENVGLIVRDVSLTLFKNHDGKFYLTPRTMYEPRVATSADFVRINSCATTFVNATATELPNIIPDYIDVNKTVQDMLEQYKPNWTVPNLHLDLFNLTYLNLTGEINDLENRSVTLQQTVADLQVLIDNINGTLVNLEWLNRVETYVKWPWWVWVIIGLILLIALPILLFCCLSTGCCGCCGCLTSCLAGCCKNSCKKPSYYEPMEKVHIN
Summary
Function
S1 region attaches the virion to the cell membrane by interacting with host ANPEP/aminopeptidase N, initiating the infection. Binding to the receptor probably induces conformational changes in the S glycoprotein unmasking the fusion peptide of S2 region and activating membranes fusion. S2 region belongs to the class I viral fusion protein. Under the current model, the protein has at least 3 conformational states: pre-fusion native state, pre-hairpin intermediate state, and post-fusion hairpin state. During viral and target cell membrane fusion, the coiled coil regions (heptad repeats) regions assume a trimer-of-hairpins structure, positioning the fusion peptide in close proximity to the C-terminal region of the ectodomain. The formation of this structure appears to drive apposition and subsequent fusion of viral and target cell membranes.
Subunit
Homotrimer. During virus morphogenesis, found in a complex with M and HE proteins. Interacts with host ANPEP.
Similarity
Belongs to the alphacoronaviruses spike protein family.
Uniprot
EMBL
ProteinModelPortal
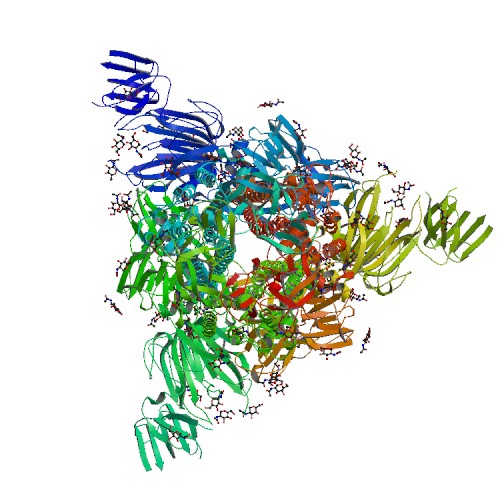
PDB
6U7K
E-value=0.0 Score= 981 Identity=47.09%
Cov(Q)=84.30% Cov(P)=87.13%
3D Structure
Ontologies
GO
GO:0046813 P:receptor-mediated virion attachment to host cell
GO:0039654 P:fusion of virus membrane with host endosome membrane
GO:0009405 P:pathogenesis
GO:0019064 P:fusion of virus membrane with host plasma membrane
GO:0044173 C:host cell endoplasmic reticulum-Golgi intermediate compartment membrane
GO:0019031 C:viral envelope
GO:0016021 C:integral component of membrane
GO:0075509 P:endocytosis involved in viral entry into host cell
GO:0055036 C:virion membrane
GO:0039654 P:fusion of virus membrane with host endosome membrane
GO:0009405 P:pathogenesis
GO:0019064 P:fusion of virus membrane with host plasma membrane
GO:0044173 C:host cell endoplasmic reticulum-Golgi intermediate compartment membrane
GO:0019031 C:viral envelope
GO:0016021 C:integral component of membrane
GO:0075509 P:endocytosis involved in viral entry into host cell
GO:0055036 C:virion membrane
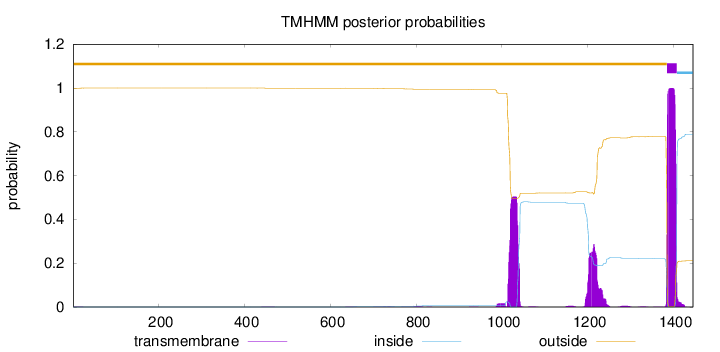
Subcellular Location
From MSLVP
Single-Pass Membrane
From Uniprot
Virion membrane
Accumulates in the endoplasmic reticulum-Golgi intermediate compartment, where it participates in virus particle assembly. With evidence from 1 publications.
Host endoplasmic reticulum-Golgi intermediate compartment membrane Accumulates in the endoplasmic reticulum-Golgi intermediate compartment, where it participates in virus particle assembly. With evidence from 1 publications.
Host endoplasmic reticulum-Golgi intermediate compartment membrane Accumulates in the endoplasmic reticulum-Golgi intermediate compartment, where it participates in virus particle assembly. With evidence from 1 publications.
Topology
Length:
1446
Number of predicted TMHs:
1
Exp number of AAs in TMHs:
42.31285
Exp number, first 60 AAs:
0.00958
Total prob of N-in:
0.00062
outside
1 - 1385
TMhelix
1386 - 1408
inside
1409 - 1446