Strain
Porcine_MN056942
(Region: France; Strain: Porcine epidemic diarrhea virus strain FR2019001, complete genome.; Date: 19-Feb)
Gene
replicase polyprotein 1ab
Description
Annotated in NCBI,
replicase polyprotein 1ab
Location
GenBank Accession
Sequence
CDS
GTGTATCGTGCTTTTGACATCTACAACAAGGATGTTGCTTGTCTAGGTAAATTCCTCAAGGTGAACTGTGTTCGCCTGAAGAATTTGGATAAGCATGATGCATTCTATGTTGTCAAAAGATGTACCAAGTCTGCGATGGAACACGAGCAATCCATCTATAGCAGACTTGAAAAGTGTGGAGCCGTAGCCGAACACGATTTCTTCACTTGGAAGGATGGTCGTGCAATCTATGGTAACGTTTGTAGAAAGGATCTTACCGAGTATACTATGATGGATTTGTGTTACGCTTTACGTAACTTTGATGAAAACAATTGCGATGTTCTTAAGAGCATTTTAATTAAGGTAGGCGCTTGTGAGGAGTCCTACTTCAATAATAAAGTCTGGTTTGACCCTGTTGAAAATGAAGACATTCATCGTGTCTATGCATTGTTAGGTACCATTGTTTCACGTGCTATGCTTAAATGCGTTAAGTTCTGTGATGCAATGGTTGAACAAGGTATAGTTGGTGTTGTCACATTAGATAATCAGGATCTTAATGGTGATTTTTATGATTTTGGTGATTTTACTTGTAGCATCAAGGGAATGGGTATACCCATTTGCACATCATATTACTCTTATATGATGCCTGTTATGGGTATGACTAATTGCCTTGCTAGTGAGTGTTTTGTTAAGAGTGATATATTTGGTGAGGATTTCAAGTCATATGACCTGCTGGAATATGATTTCACGGAGCATAAGACAGTACTCTTCAACAAGTATTTCAAGTATTGGGGACTGCAATACCACCCTAACTGTGTGGACTGCAGTGATGAGCAGTGCATAGTTCACTGTGCCAACTTCAATACATTGTTTTCCACTACTATACCTATTACGGCATTTGGACCTTTGTGTCGCAAGTGTTGGATTGATGGTGTTCCACTGGTAACTACAGCTGGTTATCATTTTAAACAGTTAGGTATAGTTTGGAACAATGACCTCAACTTACACTCTAGCAGGCTCTCTATTAACGAACTACTCCAGTTTTGTAGTGATCCTGCATTGCTTATAGCATCATCACCAGCCCTTGTTGATCAGCGTACTGTTTGCTTTTCAGTTGCAGCGCTAGGTACAGGTATGACTAACCAGACTGTTAAACCTGGCCATTTCAATAAGGAGTTTTATGACTTCTTACTTGAGCAAGGTTTCTTTTCTGAGGGTTCTGAGCTTACTTTAAAGCACTTCTTCTTTGCACAGAAGGGTGATGCAGCTGTTAAGGATTTTGACTACTATAGGTATAATAGACCTACTGTTCTGGACATTTGCCAAGCTCGCGTCGTGTATCAAATAGTGCAACGCTATTTTGATATTTACGAAGGTGGTTGTATCACTGCTAAAGAAGTGGTTGTTACAAACCTTAACAAGAGCGCAGGTTATCCTTTGAACAAGTTTGGTAAAGCTGGTCTTTACTATGAGTCTTTATCCTATGAGGAACAGGATGAACTTTATGCTTATACTAAGCGTAACATCCTGCCCACTATGACACAGCTCAACCTTAAATATGCTATAAGTGGCAAAGAACGTGCACGCACAGTGGGTGGTGTTTCGCTTTTGTCAACCATGACTACTCGGCAGTATCACCAGAAACACCTTAAGTCCATAGTTAATACTAGGGGCGCTTCGGTTGTTATTGGTACTACTAAGTTTTATGGTGGTTGGGACAACATGCTTAAGAACCTTATTGATGGTGTTGAAAATCCGTGTCTTATGGGTTGGGATTACCCAAAGTGCGACAGAGCACTGCCCAATATGATACGCATGATTTCAGCCATGATTTTAGGCTCTAAGCACACCACATGCTGCAGTTCCACTGACCGGTTTTTCAGGTTGTGCAATGAATTGGCTCAAGTCCTTACTGAGGTTGTTTATTCTAATGGAGGTTTTTATTTGAAGCCAGGTGGTACTACCTCTGGTGATGCAACCACCGCATATGCAAACTCAGTTTTCAATATCTTCCAAGCAGTAAGTGCCAATGTTAACAAACTTCTTAGTGTTGACAGCAATGTCTGTCATAATTTAGAAGTTAAGCAATTGCAGCGTAAGCTTTATGAGTGCTGTTATAGATCAACTACCGTCGATGACCAGTTCGTCGTTGAGTATTATGGTTACTTGTGTAAACATTTTTCAATGATGATTCTTTCTGATGATGGCGTTGTTTGTTACAACAATGACTATGCATCACTTGGTTATGTCGCTGATCTTAACGCATTCAAGGCTGTTTTGTATTACCAGAACAATGTCTTCATGAGCGCCTCTAAATGTTGGATCGAGCCCGACATTAATAAAGGTCCTCATGAATTTTGCTCGCAGCATACTATGCAGATTGTCGATAAAGATGGTACTTATTACCTACCTTACCCTGATCCTTCAAGAATCCTCTCTGCAGGTGTGTTTGTTGACGACGTTGTTAAAACTGATGCAGTTGTATTGCTTGAACGTTATGTGTCATTGGCTATAGATGCCTACCCGTTATCTAAGCATGAAAACCCTGAATATAAGAAGGTGTTTTATGTGCTTTTGGATTGGGTTAAGCACCTGTATAAAACTTTGAATGCTGGTGTGTTAGAGTCTTTTTCTGTCACACTTTTGGAAGATTCTACTGCTAAATTCTGGGATGAGAGCTTTTATGCCAACATGTATGAGAAATCTGCAGTTTTGCAATCTGCAGGGCTTTGTGTTGTTTGTGGCTCTCAAACTGTTTTACGTTGTGGTGATTGTCTACGGCGTCCTATGCTTTGTACTAAGTGTGCTTATGATCATGTCATTGGAACAACTCACAAGTTCATTTTGGCTATCACTCCATATGTGTGTTGTGCTTCAGATTGTGGTGTCAATGATGTAACTAAGCTCTACTTAGGTGGTCTTAGTTATTGGTGTCACGAACACAAGCCACGTCTTGCATTCCCGTTGTGTTCTGCTGGTAATGTTTTCGGTTTGTACAAAAATTCTGCTACCGGCTCACCCGATGTCGAGGACTTTAATCGCATTGCTACATCCGACTGGACTGATGTTTCTGACTACAGGTTGGCAAATGATGTCAAAGACTCATTGCGTCTATTTGCAGCGGAAACCATCAAGGCCAAGGAGGAGAGCGTTAAGTCATCCTACGCTTGTGCAACACTACATGAGGTTGTAGGACCTAAAGAGTTGTTGCTCAAATGGGAAGTCGGCAGACCCAAACCACCTCTTAATAGAAATTCGGTTTTCACTTGTTATCATATAACGAAGAACACCAAATTTCAAATCGGTGAGTTTGTGTTTGAGAAGGCAGAATATGATAATGATGCTGTAACATATAAAACTACCGCCACAACAAAACTTGTTCCTGGCATGGTTTTTGTGCTTACCTCACATAATGTTCAGCCATTGCGCGCACCGACCATTGCTAATCAAGAACGTTATTCCACTATACATAAGTTGYATCCTGCTTTTAACATACCTGAAGCTTATTCTAGCTTAGTGCCCTATTACCAACTGATTGGTAAGCAGAAGATTACAACTATCCAGGGACCTCCCGGTAGTGGTAAATCTCACTGTGTTATAGGGCTAGGTTTGTACTATCCAGGTGCACGTATAGTGTTTACAGCTTGTTCTCATGCAGCGGTCGATTCACTTTGTGTGAAAGCCTCCACTGCTTATAGCAATGACAAATGTTCACGCATCATACCACAGCGTGCTCGTGTTGAGTGTTATGACGGTTTCAAGTCCAATAATACTAGTGCTCAGTACCTTTTCTCCACTGTCAATGCTTTGCCAGAGTGCAATGCGGACATTGTTGTGGTGGATGAGGTCTCTATGTGCACTAATTATGACTTGTCTGTCATAAATCAGCGCATCAGCTATAGGCATGTAGTCTATGTTGGTGACCCTCAACAGCTGCCTGCACCACGTGTTATGATTTCACGTGGTACTTTGGAACCAAAGGACTACAACGTTGTCACTCAACGCATGTGTGCCCTTAAGCCTGATGTCTTCTTGCACAAGTGTTATCGCTGTCCTGCTGAGATAGTGCGCACTGTGTCTGAGATGGTCTATGAAAACCAATTCATTCCCGTGCACCCAGATAGCAAGCAGTGTTTTAAAATCTTTTGCAAGGGTAATGTTCAGGTTGACAATGGTTCAAGCATTAATCGCAGGCAATTGGATGTTGTGCGTATGTTTTTGGCTAAAAACCATAGGTGGTCAAAGGCTGTTTTTATTTCTCCTTATAACAGCCAGAATTATGTTGCCAGCCGCATGCTAGGTTTACAAATTCAGACAGTTGACTCATCCCAGGGTAGTGAGTATGACTATGTCATTTATACACAAACTTCAGATACTGCCCATGCATGTAATGTTAACAGGTTTAATGTTGCCATCACAAGGGCTAAGAAAGGCATATTATGTATAATGTGCGATAGGTCCCTTTTTGATGTGCTTAAATTTTTTGAGCTTAAATTGTCTGATTTGCAGTCTAATGAGGGTTGTGGTCTTTTTAAAGACTGTAGCAGAGGTGATGATCTGTTGCCACCATCTCACGCTAACACCTTCATGTCTTTAGCGGACAATTTTAAGACTGATCAAGATCTTGCTGTTCAAATAGGTGTTAATGGACCCATTAAATATGAGCATGTTATCTCGTTTATGGGCTTCCGTTTTGATATCAACATACCCAACCATCACACTCTCTTTTGCACACGCGACTTTGCCATGCGCAATGTTAGAGGTTGGTTGGGTTTTGACGTTGAAGGAGCACATGTTGTTGGCTCTAACGTCGGTACAAATGTCCCATTGCAATTAGGGTTTTCTAACGGTGTTGATTTTGTTGTCAGACCTGAAGGTTGCGTTGTAACTGAGTCTGGTGACTACATTAAACCCGTCAGAGCTCGTGCTCCACCAGGGGAACAATTTGCACACCTTTTGCCTCTACTTAAACGCGGCCAACCATGGGATGTGGTTCGTAAGCGTATAGTGCAAATGTGTAGTGACTACCTGGCTAACCTATCAGACATACTAATTTTTGTGTTGTGGGCTGGTGGTTTGGAGTTGACAACTATGCGTTACTTTGTCAAGATTGGACCAAGCAAGAGTTGTGATTGTGGTAAGGTTGCTACTTGTTACAATAGTGCGCTGCATACGTACTGTTGTTTCAAACATGCCCTTGGTTGTGATTACCTGTACAATCCATACTGTATTGATATACAGCAGTGGGGATACAAGGGATCACTTAGCCTTAACCACCATGAGCATTGTAATGTACATAGAAACGAGCATGTGGCTTCTGGTGATGCCATAATGACTCGCTGTCTAGCCATACATGATTGCTTTGTCAAGAACGTTGACTGGTCCATCACATACCCATTTATTGGTAATGAGGCTGTTATTAATAAGAGCGGCCGAATTGTGCAATCACACACTATGCGGTCAGTTCTTAAGTTATACAATCCAAAAGCCATATATGATATTGGCAACCCTAAGGGCATTAGATGTGCCGTAACGGATGCTAAGTGGTTCTGCTTTGACAAGAATCCTACTAATTCTAATGTCAAGACATTGGAGTATGACTATATAACACACGGCCAATTTGATGGGTTGTGCTTGTTTTGGAATTGCAATGTGGACATGTATCCAGAATTCTCTGTGGTCTGTCGGTTTGACACTCGCTGTAGGTCACCACTCAACTTGGAGGGTTGTAATGGTGGTTCACTGTATGTTAATAATCATGCATTCCATACACCGGCTTTTGACAAGCGTGCTTTTGCCAAGTTGAAGCCAATGCCATTTTTCTTCTATGATGATACTGAGTGTGACAAGTTACAGGACTCTATAAACTACGTTCCTCTTAGGGCTAGTAATTGCATTACTAAATGTAATGTTGGTGGAGCTGTCTGTAGTAAGCATTGTGCTATGTACCATAGCTATGTTAATGCTTACAACACCTTTACGTCGGCGGGCTTTACGATTTGGGTGCCCACTTCGTTTGACACCTACAATCTGTGGCAGACATTTAGTAACAACTTGCAAGGTCTTGAGAACATTGCTTTCAATGTCGTAAAGAAAGGATCTTTTGTTGGTGTTGAAGGTGAGCTTCCTGTAGCTGTGGTTAACGACAAAGTGCTCGTTAGAGATGGTACTGTTGATACTCTTGTTTTCACAAACAAGACATCACTACCCACTAACGTAGCTTTTGAGTTGTATGCCAAGCGTAAGGTAGGACTCACCCCACCCATTACGATCCTACGTAACTTGGGTGTTGTTTGCACATCTAAGTGTGTCATCTGGGACTATGAAGCCGAACGTCCACTTACTACTTTTACAAAGGATGTCTGTAAATATACCGACTTTGAGGGTGACGTTTGCACACTCTTTGATAACAGCATTGTTGGTTCATTAGAGCGATTCTCTAGGACCCAAAATGCTGTGCTTATGTCACTTACAGCTGTTAAAAAGCTTACTGGCATAAAGTTAACTTATGGTTATCTTAATGGTGTCCCAGTTAACACACATGAAGATAAACCTTTTACTTGGTACATTTACACTAGGAAGAACGGCAAGTTCGAGGACTATCCTGATGGCTATTTTACCCAAGGTAGAACAACCGCTGATTTTAGCCCTCGTAGTGACATGGAACGGGACTTCCTAAGTATGGATATGGGTCTGTTTATTAACAAGTATGGACTCGAAGATTACGGCTTTGAGCACGTTGTGTATGGTGATGTTTCTAAAACCACCCTTGGTGGTTTACATCTACTAATTTCGCAGGTGCGTCTGGCCTGTATGGGTGTGCTTAAAATAGACGAGTTTGTGTCTAGTAATGATAGCACGTTAAAGTCTTGTACTGTTACATATGTTGATAACCCTAGTAGTAAGATGGTTTGCACGTATATGGATCTCCTTCTTGACGATTTTGTCAGCATTCTTAAATCGTTGGATTTGAGTGTTGTATCTAAAGTTCATGAAGTTATGGTCGATTGTAAAATGTGGAGGTGGATGTTGTGGTGTAAGGATCATAAACTCCAGACATTTTATCCGCAACTTCAGGCCAGTGAATGGAAGTGTGGTTATTCCATGCCTTCTATTTACAAGATACAACGTATGTGTTTAGAATCTTGCAATCTCTATAACTATGGTGCTGGTATTAAGTTACCTGATGGCATTATGTTTAACGTAGTTAAATATACACAGCTTTGTCAATATCTTAATAGCACCACAATGTGTGTACCCCATCACATGCGCGTGCTACATCTTGGTGCTGGCTCCGACAAGGGTGTTGCACCTGGCACGGCTGTCTTACGACGTTGGTTGCCACTGGATGCCATTATAGTTGACAATGATAGTGTGGATTACGTTAGCGATGCTGATTATAGTGTTACGGGAGATTGCTCTACCTTATACCTGTCAGATAAGTTTGACTTAGTTATATCTGATATGTATGATGGTAAGATTAAAAGTTGTGATGGGGAGAACGTGTCTAAAGAAGGCTTCTTTCCCTATATTAATGGTGTCATCACTGAAAAGTTGGCACTTGGTGGTACTGTAGCTATTAAGGTGACGGAGTTTAGTTGGAATAAGAAGTTGTATGAACTCATTCAGAAGTTTGAGTATTGGACAATGTTCTGTACCAGTGTTAACACGTCATCGTCAGAGGCATTTTTAATTGGTGTTCACTATTTAGGTGATTTTGCAAGTGGTGCTGTGATTGACGGCAACACTATGCATGCCAATTATATCTTCTGGCGTAATTCCACAATTATGACTRTGTCTTACAATAGTGTACTTGATTTAAGCAAGTTCAATTGTAAGCATAAGGCTACAGTTGTTATTAATTTAAAAGATTCATCCATTAGTGATGTTGTGTTAGGTTTGTTGAAGAATGGTAAGTTGCTAGTGCGTAATAATGACGCCATTTGTGGTTTTTCTAATCATTTGGTCAACGTAAACAAATGA
Protein
VYRAFDIYNKDVACLGKFLKVNCVRLKNLDKHDAFYVVKRCTKSAMEHEQSIYSRLEKCGAVAEHDFFTWKDGRAIYGNVCRKDLTEYTMMDLCYALRNFDENNCDVLKSILIKVGACEESYFNNKVWFDPVENEDIHRVYALLGTIVSRAMLKCVKFCDAMVEQGIVGVVTLDNQDLNGDFYDFGDFTCSIKGMGIPICTSYYSYMMPVMGMTNCLASECFVKSDIFGEDFKSYDLLEYDFTEHKTVLFNKYFKYWGLQYHPNCVDCSDEQCIVHCANFNTLFSTTIPITAFGPLCRKCWIDGVPLVTTAGYHFKQLGIVWNNDLNLHSSRLSINELLQFCSDPALLIASSPALVDQRTVCFSVAALGTGMTNQTVKPGHFNKEFYDFLLEQGFFSEGSELTLKHFFFAQKGDAAVKDFDYYRYNRPTVLDICQARVVYQIVQRYFDIYEGGCITAKEVVVTNLNKSAGYPLNKFGKAGLYYESLSYEEQDELYAYTKRNILPTMTQLNLKYAISGKERARTVGGVSLLSTMTTRQYHQKHLKSIVNTRGASVVIGTTKFYGGWDNMLKNLIDGVENPCLMGWDYPKCDRALPNMIRMISAMILGSKHTTCCSSTDRFFRLCNELAQVLTEVVYSNGGFYLKPGGTTSGDATTAYANSVFNIFQAVSANVNKLLSVDSNVCHNLEVKQLQRKLYECCYRSTTVDDQFVVEYYGYLCKHFSMMILSDDGVVCYNNDYASLGYVADLNAFKAVLYYQNNVFMSASKCWIEPDINKGPHEFCSQHTMQIVDKDGTYYLPYPDPSRILSAGVFVDDVVKTDAVVLLERYVSLAIDAYPLSKHENPEYKKVFYVLLDWVKHLYKTLNAGVLESFSVTLLEDSTAKFWDESFYANMYEKSAVLQSAGLCVVCGSQTVLRCGDCLRRPMLCTKCAYDHVIGTTHKFILAITPYVCCASDCGVNDVTKLYLGGLSYWCHEHKPRLAFPLCSAGNVFGLYKNSATGSPDVEDFNRIATSDWTDVSDYRLANDVKDSLRLFAAETIKAKEESVKSSYACATLHEVVGPKELLLKWEVGRPKPPLNRNSVFTCYHITKNTKFQIGEFVFEKAEYDNDAVTYKTTATTKLVPGMVFVLTSHNVQPLRAPTIANQERYSTIHKLXPAFNIPEAYSSLVPYYQLIGKQKITTIQGPPGSGKSHCVIGLGLYYPGARIVFTACSHAAVDSLCVKASTAYSNDKCSRIIPQRARVECYDGFKSNNTSAQYLFSTVNALPECNADIVVVDEVSMCTNYDLSVINQRISYRHVVYVGDPQQLPAPRVMISRGTLEPKDYNVVTQRMCALKPDVFLHKCYRCPAEIVRTVSEMVYENQFIPVHPDSKQCFKIFCKGNVQVDNGSSINRRQLDVVRMFLAKNHRWSKAVFISPYNSQNYVASRMLGLQIQTVDSSQGSEYDYVIYTQTSDTAHACNVNRFNVAITRAKKGILCIMCDRSLFDVLKFFELKLSDLQSNEGCGLFKDCSRGDDLLPPSHANTFMSLADNFKTDQDLAVQIGVNGPIKYEHVISFMGFRFDINIPNHHTLFCTRDFAMRNVRGWLGFDVEGAHVVGSNVGTNVPLQLGFSNGVDFVVRPEGCVVTESGDYIKPVRARAPPGEQFAHLLPLLKRGQPWDVVRKRIVQMCSDYLANLSDILIFVLWAGGLELTTMRYFVKIGPSKSCDCGKVATCYNSALHTYCCFKHALGCDYLYNPYCIDIQQWGYKGSLSLNHHEHCNVHRNEHVASGDAIMTRCLAIHDCFVKNVDWSITYPFIGNEAVINKSGRIVQSHTMRSVLKLYNPKAIYDIGNPKGIRCAVTDAKWFCFDKNPTNSNVKTLEYDYITHGQFDGLCLFWNCNVDMYPEFSVVCRFDTRCRSPLNLEGCNGGSLYVNNHAFHTPAFDKRAFAKLKPMPFFFYDDTECDKLQDSINYVPLRASNCITKCNVGGAVCSKHCAMYHSYVNAYNTFTSAGFTIWVPTSFDTYNLWQTFSNNLQGLENIAFNVVKKGSFVGVEGELPVAVVNDKVLVRDGTVDTLVFTNKTSLPTNVAFELYAKRKVGLTPPITILRNLGVVCTSKCVIWDYEAERPLTTFTKDVCKYTDFEGDVCTLFDNSIVGSLERFSRTQNAVLMSLTAVKKLTGIKLTYGYLNGVPVNTHEDKPFTWYIYTRKNGKFEDYPDGYFTQGRTTADFSPRSDMERDFLSMDMGLFINKYGLEDYGFEHVVYGDVSKTTLGGLHLLISQVRLACMGVLKIDEFVSSNDSTLKSCTVTYVDNPSSKMVCTYMDLLLDDFVSILKSLDLSVVSKVHEVMVDCKMWRWMLWCKDHKLQTFYPQLQASEWKCGYSMPSIYKIQRMCLESCNLYNYGAGIKLPDGIMFNVVKYTQLCQYLNSTTMCVPHHMRVLHLGAGSDKGVAPGTAVLRRWLPLDAIIVDNDSVDYVSDADYSVTGDCSTLYLSDKFDLVISDMYDGKIKSCDGENVSKEGFFPYINGVITEKLALGGTVAIKVTEFSWNKKLYELIQKFEYWTMFCTSVNTSSSEAFLIGVHYLGDFASGAVIDGNTMHANYIFWRNSTIMTXSYNSVLDLSKFNCKHKATVVINLKDSSISDVVLGLLKNGKLLVRNNDAICGFSNHLVNVNK
Summary
Catalytic Activity
ATP + H2O = ADP + H(+) + phosphate
a ribonucleoside 5'-triphosphate + RNA(n) = diphosphate + RNA(n+1)
a ribonucleoside 5'-triphosphate + RNA(n) = diphosphate + RNA(n+1)
Similarity
Belongs to the coronaviruses polyprotein 1ab family.
Uniprot
Proteomes
Pfam
Interpro
IPR036333
NSP10_sf
IPR014828 NSP7
IPR027352 CV_ZBD
IPR037204 NSP7_sf
IPR008740 Peptidase_C30
IPR009469 RNA_pol_N_coronovir
IPR032505 Corona_NSP4_C
IPR009466 NSP11
IPR036499 NSP9_sf
IPR041679 DNA2/NAM7-like_AAA
IPR029063 SAM-dependent_MTases
IPR027351 (+)RNA_virus_helicase_core_dom
IPR018995 RNA_synth_NSP10_coronavirus
IPR013016 Peptidase_C30/C16
IPR014827 Viral_protease
IPR009461 Coronavirus_NSP16
IPR002589 Macro_dom
IPR027417 P-loop_NTPase
IPR037230 NSP8_sf
IPR038123 NSP4_C_sf
IPR042515 Nsp15_N
IPR011050 Pectin_lyase_fold/virulence
IPR037227 EndoU-like
IPR014829 NSP8
IPR009003 Peptidase_S1_PA
IPR014822 NSP9
IPR014828 NSP7
IPR027352 CV_ZBD
IPR037204 NSP7_sf
IPR008740 Peptidase_C30
IPR009469 RNA_pol_N_coronovir
IPR032505 Corona_NSP4_C
IPR009466 NSP11
IPR036499 NSP9_sf
IPR041679 DNA2/NAM7-like_AAA
IPR029063 SAM-dependent_MTases
IPR027351 (+)RNA_virus_helicase_core_dom
IPR018995 RNA_synth_NSP10_coronavirus
IPR013016 Peptidase_C30/C16
IPR014827 Viral_protease
IPR009461 Coronavirus_NSP16
IPR002589 Macro_dom
IPR027417 P-loop_NTPase
IPR037230 NSP8_sf
IPR038123 NSP4_C_sf
IPR042515 Nsp15_N
IPR011050 Pectin_lyase_fold/virulence
IPR037227 EndoU-like
IPR014829 NSP8
IPR009003 Peptidase_S1_PA
IPR014822 NSP9
SUPFAM
ProteinModelPortal
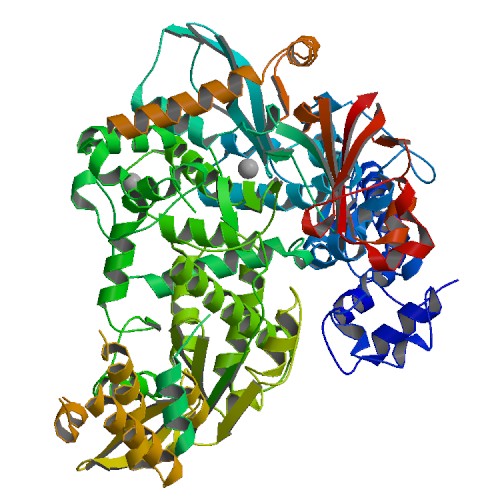
PDB
6NUS
E-value=0.0 Score=1139 Identity=59.53%
Cov(Q)=34.00% Cov(P)=94.45%
3D Structure
Ontologies
GO
GO:0005524 F:ATP binding
GO:0008270 F:zinc ion binding
GO:0019082 P:viral protein processing
GO:0006351 P:transcription, DNA-templated
GO:0003723 F:RNA binding
GO:0016896 F:exoribonuclease activity, producing 5'-phosphomonoesters
GO:0044220 C:host cell perinuclear region of cytoplasm
GO:0008242 F:omega peptidase activity
GO:0016021 C:integral component of membrane
GO:0003968 F:RNA-directed 5'-3' RNA polymerase activity
GO:0033644 C:host cell membrane
GO:0019079 P:viral genome replication
GO:0008168 F:methyltransferase activity
GO:0004197 F:cysteine-type endopeptidase activity
GO:0003724 F:RNA helicase activity
GO:0039520 P:induction by virus of host autophagy
GO:0008270 F:zinc ion binding
GO:0019082 P:viral protein processing
GO:0006351 P:transcription, DNA-templated
GO:0003723 F:RNA binding
GO:0016896 F:exoribonuclease activity, producing 5'-phosphomonoesters
GO:0044220 C:host cell perinuclear region of cytoplasm
GO:0008242 F:omega peptidase activity
GO:0016021 C:integral component of membrane
GO:0003968 F:RNA-directed 5'-3' RNA polymerase activity
GO:0033644 C:host cell membrane
GO:0019079 P:viral genome replication
GO:0008168 F:methyltransferase activity
GO:0004197 F:cysteine-type endopeptidase activity
GO:0003724 F:RNA helicase activity
GO:0039520 P:induction by virus of host autophagy
Subcellular Location
From MSLVP
Capsid
From Uniprot
Host cytoplasm
Host perinuclear region
Host membrane
Host perinuclear region
Host membrane
Topology
Length:
2653
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.295110000000002
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00785
outside
1 - 2653

