Strain
Snake_NC_035465
(Region: Switzerland; Strain: Morelia viridis nidovirus strain S14-1323_MVNV, complete genome.; Date: 2014)
Gene
ORF1b
Description
Annotated in NCBI,
ORF1b
Location
GenBank Accession
Sequence
CDS
AAAACTCCGCAGACTGCGAGAGCAGGCAAAAAACTCGTCTCGTCCGCAGTGAAGCAGGTCACTGGGGACTACGATCTTGTTCTCAAACAAGTATCCGACATCCTGCAACAACCTCAACTCCACCGCACCGTACAAGACGACGAACAACACGACAACGAAGGCCACTGGGTCAATGTCTGTCAGCAAGACTGTGGAATCAAACGGCTCAACAAGTGCCGCACAACAAGCATCCAGATTAACAACCGCAACCACATGCTCAAGACCGGCACCGAGGAGGACCTCAGGCACGAATACAACCAGTATGTCGCGCTCAAAGACCTCATCGCAATACCAGAACACAAACTCATTAGACTCAAGAATAACAGCTACATCCTCATCCGAGGACCAGTGACCAAAAAGTCACTTGGAGACTTAGTCTATTCACACCTGCACAACCAGACTGCCGACGCCGTCGAGATACCTGACAAGGGCAATCCAACAACTGCACAACAACTCGGAGACGAACTCGCCAACACACTCAAGCCAGCATTCGACAACCTCGATAAACTGCGAGAGTGGTGTTATGCGTATGACGTTCAGATGCCAATCACACTCGACAACATCGACTTAGAGGGTCAGCTGTACGATTTTGGTGACATGAATACAAGTCCACATAACATCGACATCGCACTCAGCGACCTAATGCGACTCTGGTCTCTCACGAACCAACCAGCACCATCAGTCGTCAAGAAGTGGTTTCCAGTCAGGTATGACTTCACCGAATGTGGTTGGCTCGATAAGGTCTTGCAGATCAATAACAATCTACTGCACGCTCGCAACACTAACACCGAGATCTTCATCGATGCCACAAGTAACATCACGAGAATGTACCATAACGAAGTCACAGGCACCCACACGATCGACGCACAGCAGCTCGAGAGCTGTTCCGATTATCTCCAGAACTTGTACTATCTGCAAGATCCGGGGTTACATTGGCGCAAACCGATCGTCACTATCGGAGACCGAGTCAACTTTGCAGCAACAACCGACAACACCGACACCACAGCGAACCGACCAGTCTACTACAACGAAGAAGCATTCAACTTCTTCGAGTCTAGACTCGGTAACATCGACCCCGTTCTCGACTATACGTACTTCCAGGGTGACAACAACGACTGTGTCAACGACTTCTTGTTCTATGACTACCAAGGCAGGTTATTCTTACAACCACACATCATCAGGTTCCTCTACGAGCGTACACGCAAAGACTTTAGCTCATGCGCAACCGACGCAAGGTTCAGCAAACTCGAGTGTACACCACGCAAGAGTTCACTCGGGCCATCTCACATGTTGTTAAGGTCTTATAAGCAGAACCAAGTGTACGAAGCAGCACCAGACAACTTCATCGAAGAACTCGTCAACCTGTCCCACCACAGCGCAATGATCTTCAGTACGAAATGTGTTCAAAAATTCGCTCTGACATCGAAACCACGAGCCAGGACGATCGCAGCATGCTCCATGATCGCATCTACACTCTTCCGAGCACTCCACAAGCCAGTCACCGCCAACTTCGTCACACAGACACAGAAGGCAGGTACCGACATCCACCACCTCATCGGAGTCACAAAATTCCGAGGAGGATTCCACAACTGGTTCACCTCAAGACACGGTGATATCAGCAACTGGAAGATTTTCGGTAGTGATTATACCAAATGTGACCGTAGCTTTCCACTCGTCTTTCGCAGCATGGCAGCAGCCTTGCTGTTTGATCTCGGAGGTTGGGATCCTTATTCCCACCACTTCACCAACGAAGTGCATGCTTTCATGTTTGACATGGTCCATCTCGACGGGAAGATCGTCTATAAACCAGGAGGCACAAGTAGCGGCGATGCAACAACAGCTTTCGCCAACACACTGTACAATCACTGTGTTCATCTTCTCGTGCAGCTTCAAACACTAGTCACACAACAGGTCCACACCAACCACCTCGCATTCAAGGTCGCAGCAGTCAAGGGTTTCCAAACAGGAGACTTCGATGACTATGACCAAATGCTCGACCTGTATAACAAGAAACACTACAAGTTCAACTTTCTCAGCGACGATAGCTTCATCTTGACTAACATCCACGACAGCACGCTACCTGACATCTACAACAAGCATAACTTTAGCAAGCATCTCGAGACCATTATCCACACTAAGGTCGACCAGAACAAAGCGTGGGAATCAAAAGGAGATCTCCACGAGTTCTGTTCTAGTACAGTCAAGCCATGTAACGGCATCTTGCAGTACATCCCAGACAAGAATAGGCTGCTTGCAGCACTCTGTATCGAAGGTAAAGCTTCAACAGCCGAACTCCGAGTCGTCAGAACAGCTGCCATTCTCGCCGAAGCAGTCATCTACTCACAAGTCGACGTCAACTTCTGGCGCGTGCTATGGGAGTACTTTGAAAACCAACTCGCAGAATTCATCGATAATTACGGCGTCTTACCAATACCAGACAAGATGACTGAAGCAGACTTTTATTATGGACTCATCGACCCAACCAAGTCACCAACAGACCTCGAGATCTTTCAGGCAGTGCTCGCAGAATGGGGTATTCAAGACATCGAAACCCAAGCCAAGAACCAGGTCCAGCAGCAATGCTATACCTGTCACAACCCGACAGTCAGTACCTGTATCGACTGTCCAGTTGCTTATCCACTCTGTTGTTTTTGTGCCTGTACCCACTACCACGAAACAGGCCACAAAGTAACACACCTGCCAGTCTGTTCACATCCAGGCTGTGGTATGTCAGACCCAGAACTCATGAACTTTTCTCTCGCCAACGGCCAATTCACAATCCGCTGTAACGACCACGACACCGACTTCAGCATCAAGGTCTATGATAACAAGACACAAAGCTTTAGGCTGCCACTCAATCAGTACTGCGTCAAGCAGGATTCTACAGTCTCTAACATCAGCAAGACGATCGACAACTTCACCGAGGGTAACTTCTTCGGTTGGGATGTCAATGAGAATAGCCACAGCAACATGGTTAGGCTCATCCATGAATCCTATCTCAACGACCAGTATAGCATCGAGCAGGATGTCATCTATGACTATGTAGTCTTAGACGTTAAGAACAACGAAGTGATGATCAAAGATGCCTCTTATGGCCTCACAACTTACTGTAACATCCTCGACAACGCAGGAAAAGTCAAACTCAACTGCACAGTCGACCCACTCCGCAAGGACATCTACAAGCTCACCTTTCTCGACGATACGAAAAGGTTCATCAACTTCGACAAGATCCAACGCAGCAACAGACTCGCCACGAAAACAGACTTGGCATTACTCGATGTCTTTAAGAGAACTAAGTTCATTCTCGGGCCACCAGGAACCGGCAAGACCACGTATTTCATCGACAACTATTTCAACAAACAACGCACCAACAAGGTAGTCTATGCCGCACCTACACACAAACTAGTCCAGGACATGGACGAAGCACTCAAGGACAACACCAACGTCACAGTCTACAAGGGCAAGTATAACAACCGAGAGTACCACGCACCAATCGACGACGAGAGCAAGTCCCTCATCTTGTGTACAGTCAACATCGTCAGACCAATCGCAGGCTGTGTCTTGCTCATCGACGAGTGTTCACTCTTGTCACCGAAGCAGCTCTTCGATGCCATCATCCGCAGTCGAGCAGGCGAAGTTATCTGTGTAGGAGACCCATTCCAACTCAGTCCAGTCACACCACTCACCGACTTTAGCTGGGACTATAATACATTCTACCTCCGACAACTCGTGCCACCGTACAACCAAACCGTACTGTCCACCTGCTACCGATGTCCAAGAAACATCTTCGACATCTTCGCAGGTGCATACCACCACCACGGCATCGAGTTCAATCCAGCAAGAGAAGGAGGTACAGTAGTCTGGCACCGTCTCAAGAACGACAGCATAGTCATCAGCCAGAAGGTACTCCAGGAGGCAGACAACAGTGGATGTGATCTCATCCTCGTGAACTATAAGCAAGCAGCCATCGACGCACTCGGCCTCAAGACCAAGTTTGTCACAATAGACTCCGCACAGGGACTCACAGTCAGCAGAGTCGGCGTGGTAATCTTTGGTAGTACAAAGTTCAGCAAAGTTCTCAACAGGCTCATCGTCGCCACAAGTCGAGCGACCACACAACTCGACATCTGGTGTTGTGAGGCTGTTGAGGATCATATCCGAGAACACTTATGCACCAAGACAGTCAAACCACAGGTCCTCACAAGGCCGAGTCATCTGACACCAGTCACAATCGAGGAAGTTGCTTCCAACATCGAAGCAAGCGCAGTCTGTGACATCGAGTTCTATCACACAAGACATCCAACACGTAAGCATCCCAACTTTCTCGGTCTCGGCGAGATTAACTGCATGACAAGTCGCTCAGTCACAACTTATCTCAGACCGCACTACAACCGAGACGGTGATTACTTCGAAGTTACCGACGACTACATCTGCGTCAGTAAAGACTGGAAGTATATGCTTAGACACTTGCCGAACTATCCAGACTCCAACATGAGGCGTAACCACTTCTTGCACTTCTTGAATAGCACAACCAACCTCACCGCACACCCACTCATCTTCGTACTCTTCAACGGCAAGAACGACCTCGACGCACTCGCCGAGATTACAACACCAGCAGCTACATGTCACTGTGGCAAGCCAGCACGATTCACCACCAACACCGACGAGGATGTCTGTCAAGTGCATTGTGAAGGAAAGTTTTTAGTCGCAGTTGCAGGAGGTGCATATTTCGACATCAAAAGTACCAGCAACCTCAGCTCAACCCACGGTATCGTCTGTGGTAAGTACCACGGTACCCCACACTCAGCTAACAACGACGTAGTCATGACAGCTTGTCTTCTCGACGACATGCTGAAACAACATACAGCAGTCACCGAGGGGCCAACTAAGAGTGACGAATTTGGAGTGTGGAGGAAAGTCAAACCATCACTCGACGATCCAAACGACAGGGTCTATGGCTCAACCCACTATCACAAGAGTGCTAGACTCAAGCATAGTCACAACACAAGTATCAACAACTACATGCCAATCAACAAAGAACACACAAGCACCTACGTGATCATACCTCCAGCAATGCGCATCAAAGCATGTCATGCAGTCTCCAGAATTCACTGCTGTACTGCATGTCTTGATCACGCAAAGAAGTGGAACAAAGTCAACCATCTCAACAGCCAACAGGGATGGCAGTTCGAAAGTCAACTACTCGAACTCCAACTCTCACAACAAGAAAAGCAACTCAAGCTGTCAGCCGAAGTAATCCAGACACCGATGGGTTTGCGAGTTCGACTCGGGGACCATACAGGAGTTACAGTCAACTGGCAAGGTAGTCTCGATCAGACTATCCGAAAATTTCACAACGAAGTCAATCAACCGCTACCAGTGGCAGAGGTCTTAACAGGCCTCGCAATCAACTGCACAGTCAACTGCAGTCACCACGCAGTGCCGATTATAACCGAGGACAGACTTAACCAGTGGGACATTCCACTCGTCACGAAGGCCATCAAACACAGCGGCACCCAATATGTCTGCCAACCGGCAGGCAGGCATGCCGACAATACAAAGGCTTTCGTTCTCGGTATGGATGATTGGGTGCGTGTCAATTACGACGAGCTGCCAAGATATCAACTCACACGACTCGACAACAACACCGAAGTCGAGTTAGAGCAGTCGTTGTATAGTACCGGAAGACTTGCCACTTGTGATCATTGGCTATTTTCAAGCGAAGAAGACACAGACTGTGCTCATATCGAAATCGGTGACTATAACAACTCGTCACTCAAGATCGGAGGTATGCACATGTTTCCTAAGGCTTTCGACAACGTCAGCCTCAACAACATCGAACAGGAATCAAATACACCACTGTGGCACGCCAACATCGTTGCCAAGCAAGGCACAAAGCTGCATAACTCACTCACCGACGTCGAAGTCTCAAGATTCATTTCTGCAGTCAAAGATAAGCTATCTACCAACACGATCAGCACCAGAACAACACTCCGCATCGATCACCAGAACATTCCTATCATGATCTGGGCAACAGCAGGAAAAATCGACACAGCTTATCTCCAGAATGGAGGGCCAGACGTTCCACCATCTGTAACTCAAAAGTGTTCCCAAAGCTACATCAAGTATCAACCAGTTATCAGAGCCTACGAAACAGCTACACTCTTAAAGAGCAACATCGCCCACTTTGAAGTTGTCCGTAATAGGCTCAACCAAGCAGCTAACATCACCAAGTATGTCCAACTGTGTAACTATATCAACGATAACATCAAGGTACCTCCAAAAGCTACAGTCTTCCACATCGGCGCAGCAACAGGACCAGAGCACGACCACATCCCAGTCGGAGGTGTCGTGCTTAACCATTTTTTTACTAACAACGACGTCTACCACCACGACGTCAGGCCTATCAACAACTGCAACGGGCGATTCAAAGTCGGCTTACCTAGCCACAAGGTCGACCTCATCATCTCAGACATCTGGAGCTACGACGAGGAGAAAGACGGCGAATGGATTTCGAACCATGAACTGTTAATCAACTACGTCAATGCTCACCTATGTCTCGGTGGTAGTATCATCTGGAAAACAACCAGAAGGTCGAACCTCAGCTACATCAACTACATCGCAAGCCATTTTGGCCAGGTCGACTACATGACAACACGAGGAAACGCTAGCAGTAGTGAAATGTTTGTCGTCTTTAAGTACTTCAAACAACACATCAATCAACCACAACCATCAGACCGAGACAGTTGGCAAATCTTACACCACCTATTTGCTTTTCGACACCAGTATCGGATCTATACAAGACAAGATCCACTTAACTGTGATACCATCTGTAAGCCTAGAAGCGTCTACCGAGTACCTAAATTTCTCGAGGGGCGCATTGAAAGTTCAAGCTGGGCTAGTGGTAACTTCATTCAACAAAACTCATGA
Protein
KTPQTARAGKKLVSSAVKQVTGDYDLVLKQVSDILQQPQLHRTVQDDEQHDNEGHWVNVCQQDCGIKRLNKCRTTSIQINNRNHMLKTGTEEDLRHEYNQYVALKDLIAIPEHKLIRLKNNSYILIRGPVTKKSLGDLVYSHLHNQTADAVEIPDKGNPTTAQQLGDELANTLKPAFDNLDKLREWCYAYDVQMPITLDNIDLEGQLYDFGDMNTSPHNIDIALSDLMRLWSLTNQPAPSVVKKWFPVRYDFTECGWLDKVLQINNNLLHARNTNTEIFIDATSNITRMYHNEVTGTHTIDAQQLESCSDYLQNLYYLQDPGLHWRKPIVTIGDRVNFAATTDNTDTTANRPVYYNEEAFNFFESRLGNIDPVLDYTYFQGDNNDCVNDFLFYDYQGRLFLQPHIIRFLYERTRKDFSSCATDARFSKLECTPRKSSLGPSHMLLRSYKQNQVYEAAPDNFIEELVNLSHHSAMIFSTKCVQKFALTSKPRARTIAACSMIASTLFRALHKPVTANFVTQTQKAGTDIHHLIGVTKFRGGFHNWFTSRHGDISNWKIFGSDYTKCDRSFPLVFRSMAAALLFDLGGWDPYSHHFTNEVHAFMFDMVHLDGKIVYKPGGTSSGDATTAFANTLYNHCVHLLVQLQTLVTQQVHTNHLAFKVAAVKGFQTGDFDDYDQMLDLYNKKHYKFNFLSDDSFILTNIHDSTLPDIYNKHNFSKHLETIIHTKVDQNKAWESKGDLHEFCSSTVKPCNGILQYIPDKNRLLAALCIEGKASTAELRVVRTAAILAEAVIYSQVDVNFWRVLWEYFENQLAEFIDNYGVLPIPDKMTEADFYYGLIDPTKSPTDLEIFQAVLAEWGIQDIETQAKNQVQQQCYTCHNPTVSTCIDCPVAYPLCCFCACTHYHETGHKVTHLPVCSHPGCGMSDPELMNFSLANGQFTIRCNDHDTDFSIKVYDNKTQSFRLPLNQYCVKQDSTVSNISKTIDNFTEGNFFGWDVNENSHSNMVRLIHESYLNDQYSIEQDVIYDYVVLDVKNNEVMIKDASYGLTTYCNILDNAGKVKLNCTVDPLRKDIYKLTFLDDTKRFINFDKIQRSNRLATKTDLALLDVFKRTKFILGPPGTGKTTYFIDNYFNKQRTNKVVYAAPTHKLVQDMDEALKDNTNVTVYKGKYNNREYHAPIDDESKSLILCTVNIVRPIAGCVLLIDECSLLSPKQLFDAIIRSRAGEVICVGDPFQLSPVTPLTDFSWDYNTFYLRQLVPPYNQTVLSTCYRCPRNIFDIFAGAYHHHGIEFNPAREGGTVVWHRLKNDSIVISQKVLQEADNSGCDLILVNYKQAAIDALGLKTKFVTIDSAQGLTVSRVGVVIFGSTKFSKVLNRLIVATSRATTQLDIWCCEAVEDHIREHLCTKTVKPQVLTRPSHLTPVTIEEVASNIEASAVCDIEFYHTRHPTRKHPNFLGLGEINCMTSRSVTTYLRPHYNRDGDYFEVTDDYICVSKDWKYMLRHLPNYPDSNMRRNHFLHFLNSTTNLTAHPLIFVLFNGKNDLDALAEITTPAATCHCGKPARFTTNTDEDVCQVHCEGKFLVAVAGGAYFDIKSTSNLSSTHGIVCGKYHGTPHSANNDVVMTACLLDDMLKQHTAVTEGPTKSDEFGVWRKVKPSLDDPNDRVYGSTHYHKSARLKHSHNTSINNYMPINKEHTSTYVIIPPAMRIKACHAVSRIHCCTACLDHAKKWNKVNHLNSQQGWQFESQLLELQLSQQEKQLKLSAEVIQTPMGLRVRLGDHTGVTVNWQGSLDQTIRKFHNEVNQPLPVAEVLTGLAINCTVNCSHHAVPIITEDRLNQWDIPLVTKAIKHSGTQYVCQPAGRHADNTKAFVLGMDDWVRVNYDELPRYQLTRLDNNTEVELEQSLYSTGRLATCDHWLFSSEEDTDCAHIEIGDYNNSSLKIGGMHMFPKAFDNVSLNNIEQESNTPLWHANIVAKQGTKLHNSLTDVEVSRFISAVKDKLSTNTISTRTTLRIDHQNIPIMIWATAGKIDTAYLQNGGPDVPPSVTQKCSQSYIKYQPVIRAYETATLLKSNIAHFEVVRNRLNQAANITKYVQLCNYINDNIKVPPKATVFHIGAATGPEHDHIPVGGVVLNHFFTNNDVYHHDVRPINNCNGRFKVGLPSHKVDLIISDIWSYDEEKDGEWISNHELLINYVNAHLCLGGSIIWKTTRRSNLSYINYIASHFGQVDYMTTRGNASSSEMFVVFKYFKQHINQPQPSDRDSWQILHHLFAFRHQYRIYTRQDPLNCDTICKPRSVYRVPKFLEGRIESSSWASGNFIQQNS
Summary
Catalytic Activity
ATP + H2O = ADP + H(+) + phosphate
a ribonucleoside 5'-triphosphate + RNA(n) = diphosphate + RNA(n+1)
a ribonucleoside 5'-triphosphate + RNA(n) = diphosphate + RNA(n+1)
Uniprot
Pubmed
EMBL
Proteomes
Interpro
Gene 3D
ProteinModelPortal
PDB
6NUS
E-value=2e-33 Score= 141 Identity=24.56%
Cov(Q)=34.02% Cov(P)=82.72%
3D Structure
Ontologies
GO
GO:0003723 F:RNA binding
GO:0006351 P:transcription, DNA-templated
GO:0032259 P:methylation
GO:0003968 F:RNA-directed 5'-3' RNA polymerase activity
GO:0008168 F:methyltransferase activity
GO:0003724 F:RNA helicase activity
GO:0004197 F:cysteine-type endopeptidase activity
GO:0016896 F:exoribonuclease activity, producing 5'-phosphomonoesters
GO:0008270 F:zinc ion binding
GO:0005524 F:ATP binding
GO:0033644 C:host cell membrane
GO:0039694 P:viral RNA genome replication
GO:0006351 P:transcription, DNA-templated
GO:0032259 P:methylation
GO:0003968 F:RNA-directed 5'-3' RNA polymerase activity
GO:0008168 F:methyltransferase activity
GO:0003724 F:RNA helicase activity
GO:0004197 F:cysteine-type endopeptidase activity
GO:0016896 F:exoribonuclease activity, producing 5'-phosphomonoesters
GO:0008270 F:zinc ion binding
GO:0005524 F:ATP binding
GO:0033644 C:host cell membrane
GO:0039694 P:viral RNA genome replication
Subcellular Location
From MSLVP
Capsid
Topology
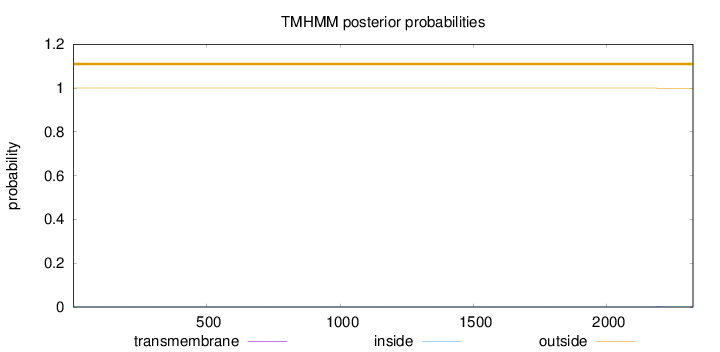
Length:
2322
Number of predicted TMHs:
0
Exp number of AAs in TMHs:
0.02544
Exp number, first 60 AAs:
0
Total prob of N-in:
0.00009
outside
1 - 2322