Strain
CHINA_BAT_2008_NC_010437
(Region: Hong Kong; Strain: Bat coronavirus 1A, complete genome.; Date: 2008)
Gene
ORF1a polyprotein
Description
Annotated in NCBI,
ORF1a polyprotein
Location
GenBank Accession
Sequence
CDS
ATGTCGTCCAACCTTGTGACATTGGCCTTTGCCAGTGATTCGGAGATTTCTGCAGAGGGTTTCTGTGATGTTAGTTCTGCCGTCTACGCTTTTAGCGTGTCCGCAGCTAACGGTTTCACAGATTGCCGTTTTGTAGCCCAAGGCTTAGAACATTGCCTTGTTGGTATTGAAGCTGATGACTACGTCCTGTGTGTAACAGGCGATGTTCAGCTTAAGGCATATATTGCCAAATTCTCGGACCGTCCTCTAAACCTTCGTGGTTGGATCGTCCGTTCTAATTCAAATTACTTTCTTGAAACCATGGATCTGGTTTTTGGCTGTGGTGGTGGCACTTCAATTCCAGTAGATAACTACATGTGTGGTGCCAACGGTAAGCCAGTTTTACCAGAAGATATGTGGTGCTTTTGCGACTATTTTGGTGATGATGGAGATAACATCACTGTAAATGGTCAAGCCTATCATAAGGCATGGAATGTCACTCGTGGTGATGTCCCATACCAGTTTCAGAATGCTAGCACTATTCTTAGCATTGAGTACCTTGCAGACGAAAAACATGTGCTGCCTGATGGTGCTGTTGCTAAGTCTGCTAAACCACCTAAGTTCTCTAAGAACATTGTTCTTTCAGAGAAATACAAAGCACTTTATGATGCTTGTGGCAATCCATTTGTCACTAATGGCACCAATGTCCTTGAGGTTGTAACCAACCCCATTTTTGCGCATGGTTTTGTGCAGTGTAAATGTGGGTCTAAACATTGGACTACTGGTGACTGGGCTGGTTTCAAATCAGTGTGCTGTGGCATACCAGGACGTGTCTTATGCACAGTCTTTGGTGGTGTTGCACCTGGTTCAGTTCTTCTGACATCAACTCGTGTTGATGCCAGCCCTGGTGCTACACGCTACTATCATGGTCTTACACTCAAACACATTTGCAATGTGGATGGTGTTGCATGCTGGCGTGTCACTAAAGTGCAGGGTGTCGAATGTTTTGTAGCTAGTGGTTCTATTGAGGACTGTGTTGGCTCCACTTTCGATACTTGTACATATGACAATTACACTTCATTTGCGAAGGCCTTTAAGTGTGGCATGCTAACTGGCAGCTTTTCTGACAATGTTGTTGCCAGTGTCATTAATGGCACACTTGATGTTGGTCTTGCAGTGCTGGATGTAACTACAGCTGTTACCAAGCCATGGTTTGTGCTGAAGTGTGGTTCACTTCTTGAATCTGCTTGGGATGCACTCATAATGGCCATTAAACAGTTACCTGTTATGGCTAGTGATGTGCTGAAGTTCTTTAACAACCTCACTCAAGTGCTGATTGTTGTTAGAAATGGTGTCATTGACATCATTCATTCTGTGCCAGAGGCTTTTAAGAGCGCCTTTGAGATCTTTAAAGACCTTGTTACAGGTGTGTTTGATCTTGTTGTTGATCACTTTAAGATCGCCAACAAAAAATTCAAGCGTGCTGGTGATTACATCCTTTTTGAAAACGCACTCGCTTGTCTTGTCAGTGGTAAGATTAAGGGTGTTAAACAAGCAGGTCTTAAAAAGCTTCTGTATGCTAAGGCTATTGTTGGTGCTACGGTTAAAGTTACTGTTAATCGTATTGAAAGTGCAACTGTCAAACTCGTTGAGTGTAAGCCATCTAACTTTGTTAAGAAAGGCAGTGCTGTTGTTATTAACAACATTGCATTTTTCCACAGTGATGGTGTTTACAGACTGATGAGTGACAGTGATGAGGTCTATGAAGACATTGCTTTTACTGCTGAAAGTGTGTCCACAGTTAAGAAACCAGTCTTTGATTGTACCAAACCAGTTGACTTTCCTGACATCAGTAGTACTGATGTTGAAGTACTGGTTCGCGAGGTCAGAGCTACTCTTGGTAAATTCTCCAGAGTCTACGACAAGTATAACTGTGTTGTCAAAGATGGAAAATGTGTTGTCACACATAGGTATGTCTTCAATGCACCTAGCTTTGTTGAAGACAAGGCTATATTTGTTGACCTCTGTAAGGATTATGTCGCAGATGTTGGCTTTGAGGCATTTTATGCTAATGCCATTGTTGCCAATAACTCTGATGAGTTTAATCCAGTTTACTCAGCTTTTGAGGTTTTCAAAACCAAAGTTGAGTGCCCTGAAGAATTTATGAATATTGATGGCGGTTCTATTTTTGGAACTTTCATCAATACAGTTAATGATGCTGTGAACTTTGTCAAATCGTTGAAGATAACGGTAACAGCTACTGAAGTCATGATCAACACTGTTAAGCGTTTCAAACGCTTTGCCAGTGCCCTTGCTAAGCTATATAGTGAGTTCATGAACACTGTCAAGAATATCATTTCTATCGGCAGTATCAAATGTTACCACTATGGCTTTGTGAAACCTGTTCTAGTGATCAAAGATATCTTTTACCGCATCTATGATGCTGCTGTAGACACATTCAATGTCGCTGTTGAAGCAGGTCTAAACACAGTTAAGACTTTCAGTGGTGGTGAAAATCCTATCACTTTCTCACGTGTTGAAGTTGCTAGTGTCGAGCTTGAACATGCTGAATATGTCAAGCCCGAAGCTAATGGTCATGTCAGTGTTATCAATGGACACACATTCTATACATGTGGTGACTATTACTACCCTTGTGACCAGAATAATTGCTTCTCACAGTGCTTTAAGAAGGTTGGTGGATCTGCTGTTACATTTTCTGAAAAAGTTGCTGTCAAACAAATTGACCCTGTTTACAAAGTAAAGCTCGTCTTCGAGTTTGAAGATGACACTATCAGTAGTGTTTGTAAGCAGGCAATTGGTAAATACATCTCTTTTGAAGGCAATGACTGGTCCAGCTTTGAGGAAACTATTCATAACGCTATGAATGTTGTTGGTGAATTCGTAGACCTACCTGATTACTTCATCTATGATGAAGAAGGTGGTCATGACTTAACTAACACTGTTATGATTTCTCAATGGCCAGTGTTTGATCCATCAGCACTACAACTTTTAGTTGCTGACTTGGGTGTCAACTGTGATTTCAATGGTAAGTCTTCCATTGAAGAATGCTTGACTTCTGTCTCTGACACTGTTCTTTGCGTGTCATTGGAAAAGTCATGTGACTGTGGCACCTTCAATGCTATAATGGAAGGGTTTGCACTTGATTTCAAACCATGCACTGATAGTGATGTCTGTGATAACTGTGGTGGTTTTTGTACTACTACTGTTTTGAGCATGACTGGTACTGGTTTTGTGCGTTCTTGTGATGAACCATTAATGCCTTTCAATGTTACATTTGAAGGTTATGGTGTTTACAAGAACGTTTGTTTTGTTAATGACACAGTGTTACCTCCTCCTTTTGATGAAGAGATCACACCTATTGAGGAAGACCTAGTAGTAGAAGATGTCATCACAGCTGATGAAGTTGTTGATGTTGAAACTACTGCACAAGTAGAAGAAGTGACTGTTGTTTCAGCTATCGAAGAGGACATTATCAAACCTGAAGAGGTTATTGATGTCTCTTCTGACATTGAAGCTGTTAATCATGCACTTTCCTTCATGAAACCTACAGAAACGAAGTTTGTAGACCCATTCAAGTTTGATTATTATGATCATGAGGGCATTCGTGTACTCAGACAGAATAATAACAATTGTTGGGTCGCTTCTACTTTGGTACAATTGCAACTTTCATGCTTGTTGGATGATGATGACACTATGGCTCTTTTTAAGGCTGGTAGTGTGTCACCATTAGTTCGCAAGTGCTATGATGCAGTTGGAGCTATTGTGGGTAGTCTAGGTGATGCATCTCATTGTTTAGAAGTTCTTTTAAAAGACCTGCATACCATGTTTATCACTTGTGATGCCACTTGTGGTTGTGGTAGCAGTAATTATGAACTTACTGGTTCTGTTTTTAGATTTATGCCTACCAGAGATAGTTTTAGTTATGGTGCTTGTGGTGTTTGTGGTAAAACACTCAAGCTTAAGATTAGAACTATGACTGGTACTGGCTTCTTTTGTCAGGACCCAAAACCTTTTAATACTGCACGTGCTATTGTAAAGCCAGTTTGTGCTAGTATTTATCAGGGTTCTACTACTAGTGGACACTATAAAACCAATGTCTTTGGCAAAAGATTTTGCGTTGATGGTTCTGGTGTTAGCAGCATTTCTAATGGCCATATTAACACGATTCTTTTGAAGGATTGTAACTATGGCATTTCTGCTATTGCTGAACCTAAGCAAGAAAAAGTTGAGCAATTTGTCACACCTGAAGATGTTGGACAAGTTGTCAAACAAAAACCTAAGCCTTTCACTATTTATCGCAATATTGAATTCTACCAAGGCGATGTTTCTGAATTAGTTGGTCTTGACTTTGACTTTATTGTCAATGCAGCCAATGAGAATCTTAAGCATGCTGGTGGAGTTGCAGCTGCGATCGACAAGCTTACTGGCAATGAATTGCAGAGTTTGTCAAATAAGTATGTAAAGACAAATGGTAAAGTCAAAGTTGGTTCTAGTGCCATGATACGTTGTAAGAAATACAGCGTACTTAATGTTGTAGGACCTAGAAAAGGTAAACATGCACCTGATCTTTTGGAAAAGTGTTATAGAACCATTCTTAAAGAGCAAGGTGTTCCTCTCACGCCTCTTATTAGTGTTGGTATATTTGGTATACCTCTTGCAACATCTTTCAATGCTCTATTGAACACGTCCAGTGGTAGAACGGTTAGATGCTTTTGCTACACTGATAAAGAGTGTAATGAGATTAAAACACTTGTTGCTTCGCTTAATGAAGAACAAGTTGCAGCTACTGTTGAAGAAACAGTTGTAGCTGAAGAAAAGCCTATTGCTGACTTAGAAACAGCTGTTGAAAGACCTGCTGAAGAAAAGTCAGTTGAAGCTGAGAAAATAGCTACCGAGGAGGTTAAAGAACCTTTGGTAGCCGAGAAAGTCATTGTTGAGGTAAATGAACCTGTTTTAAAGGTTGCTGGTGTGTCTTATTATAATATTGAAGACAGTTTTGCTGTTGGTGCTGACAATATTGTCATTCTTACTAACAGTAAATTAGAATTAGGCAAAATTGGTGAATGTATTGATAAGCATTCTGATGGTGCCTTGAAACTAGCTGTCTCTGAATATTTAAGTCAGACACCTAATGTACCTCCTGGCAATGTAATCTCAATGCGTTGTAGTGGTTTAGCCACAGTTGTGTTTGCAGTAGTTCCTAGCGATGGCGATGTCCAATATGTCAGAAATGTCAAGCGTACTATTTCCAAACTGTCAAAACTTAAGGGTTCTTCAGTTTGTTCTTTTAGTACACTTGACATGCACAAGCGTTTGTTGAACTTGTTTAACAAATTCTGTGTAGACAATATTGATGACATCAAAGACATTCACGACACAAAGACTACTATTAAAGTTAGTCTTGATGGTCGTAATGTTGTTGATGTTGATGTCGCAGCAGACCAGACTATTGGTGAACAACTCAATGCATGTACTACTGATAATGTTATTATTTCAGACAGTGTTGTAACTGATGTTATTGACACTATTGTTAATGTTGCCCCAGAAGTTGATTGGGATTCTTTTTATGGTTTCCCACATGCAGCTGAATTTCATATGCTTGACCATAGTGCTTTTGCATTTGACAATGATGTCGTTGATGGCAAACGTGCACTAGTTGGAACTGACAATAATTGCTGGATAAACGCTGTTTGTTTACAATTGCAATTTGCTGAAGTAGATTTTACTTCAGAAGGTCTTAAAGACATGTGGAATGAATTCCTGGTTGGCAATGTCGCTAAATTCTGTCACTGGATATATTGGCTTGTCAGAGCTAATAAAGGTGATGCAGGTGATGCTGAAAATGCTTTGAATATGCTTAATAAGTATGTCAAGGCACACGGCACTGTCACATTGACACGTGAAACTGCTGAAGGTTGTTGTGTTAATGAACATCGCATTAATAGCTTTGTTGTCAATGCTAGTGTTTTAAGGAGTGGTTGTAATGACGGCTATTGTAAGCATGGTAATGCTTATATAGCACGAGTCTCTAAGGTTGATGGTGTGTCAGTTATTGTTAATGTGGACAGACCTAGTGTCATGTCTGACAATTTACTTTTATCTGGCACTTCTTACACAGCCTTTTCAGGACCTATGGATTCTGGTCATTACCGCGTTTTTAATCCAGCTACATCTAAGATGTTTGATGGTGCTAATTGCATTGGTGGTGACCTTTGTAATCTTGCCGTTACAGCTGTTGTAATTAAAAACAAAGTTTTTAAAATTCAAACAGCAGATAACAACACTCCTGTAAAAATCATTAAAAAGCTTGATGATGCTTCAGAAAAGTTTTTCAGTTTTGGTGATATTGTCTCCAAGAATGTTTGCAACTCGATAATATGGTTTTTCACTATGTTAAGTATCATCTTTAGAGCTTTTAAAACCAGAGACTTTAAGGTATTTGCTCTTGCACCAGAACGCACAGGTGTCATACTTAGTAGAAGCTTAAAATATAACTTGAAGGCTGCTCAACATGTGTTGCGTCGTAAACAGACGTATGTTGAGAGATTCTTTAAGTTTAGTGTAATAGCTTACACTTTATATGCACTAAGTTTCATGTTTGTGCGCTTTAGTCCTGCTAATGATTACTTTTGTAAAGATCATGTCGAAGGTTACAGTAATTCCACTTTTGTGAAAGATGAGTACTGTGCTTCCACTATGTGTAAGGTATGCTTATTAGGGTTTCAGGAGCTTGCTGACTTGCCACACACTAAAGTTGTTTGGAAATATGTTGGCTTTCCAATTTTTGTCAATTGGTTACCGTTCTTGTACCTTGCATTCCTATTCACATTTGGTGGCATCTTTGTTAAAGGTCTTGTATGTTACTTCTTTGCTCAATATGTCAACACACTTGGTGTTTACTTTGGTATGCAAGAGAAGTTTTGGCCTTTACAGATCATTCCTTTTGACATTTTTGGTGATGAGATTGTTGTCACATTTATTGTGTACAAAGCTCTTATGTTTATCAAGCACGTTTGTTTTGGTTGTGAAAAACCATCATGTGTAGCTTGTAGTAAGAGTGCTCGTCTCAACAGAGTTCCTATGCAGACTATTGTTAATGGTGCTAATAAGTTATTTTATGTTGTTGCTAATGGTGGTTCTTCATATTGTCATAAGCACAAGTTCTTTTGCTTGAACTGCGACTCTTATGGACCTGGCAACACTTTTATTAATGAGACTGTGGCACGTGAGCTTTCCAATGTTGTTAAAACTAACGTACAACCTACAGGTGAATCTTTTATCGAAGTCGATAAAGTATCATTTGAAAATGGTTCCTACTATTTATATAGTGGTGAAACTTTTTGGCGCTATAACTTTGATGTTACAGAGGCTAAATACGGTTGTAAAGAAGTCCTCAAAAATTGTAATGTTTTGTCTGACTTCATTGTTTATAACAACACTGGTACAAACGTTTCTCAAATAAGAAATGCGTGTGTGTACTTTTCTCAGATGCTTTGCAAACCAATTAAGCTTGTTGATGCTACATTGCTTTCTACTTTGAATGTAGATTTTAATGGTGCCTTACATAGTGCATTCGTTCAGGTTCTTAATGATAGTTTCTCTAAGGATCTTTCTAGCTGTGCTAGTATGACCGAATGTAAACAAGCTTTAGGTTTTGATGTCTCGGATGAGGAATTTGTCGATGCTGTTAGTAATGCACATAGATTTAATGTGTTGCTTTCTGACAATTCTTTTAACAACCTGTTGACATCTTATGCAAAACCTGAAGAACAGTTGTCTACGCATGATGTGGCTACTTGTATGCGTTTTAATGCAAAAGTGGTCAATCATAATGTTCTTATTAAAGAAAACGTTCCTATTGTGTGGCTTGCGCGTGACTTTCAACAGCTTTCTGAAGAAGGACGTAAGTACCTTGTTAAAACTACTAAGGCCAAGGGTGTTACATTCTTATTGACATTTAATACAAATGCTATGAATGTTAAACTACCTGCTATTAGTATTGTTAACAAGAAGGGTGCTGGTGTTAGTAGTTCATTTCTATGGTGGTTATGTGCTGCTATCATTACTTTCTTTTTCTGTGTTGGCATTAGTGAAGGTCTAATTGCTACCAGTCTTGAAGGTTTTGGTTTCAAGTATATTAAAGATGGTGTTATGCATGACTTTGACAAACCTTTGAGTTGTGTACATAATGTCTTTGATAATTTCAATAGTTGGCATGAGGCCCGTTTTGGTAGTATTCCATCTAACAGCCTTAAATGTCCTATTGTTGTTGGCACCCTTGATGACGTACGTAATGTACCTGGTGTGCCTTCTGGTATATTGTTAGTTGGCAAGACACTAGTTTTTGCTATCAAAGCAGTCTTTACTGATGCTGGCAATTGTTATGGTCTTAATGGACTAACTAATGCTGGTGCTTGCCTTTTCAACTCAGCATGCACAAAACTCGAAGGCCTTGGTGGTACTCATGTTTATTGCTACAAAGACGGTTTGTTTGAGGGTTCCAAACGTTATTCTGATTTGGTTCCTCATTCTAACTATAAAATGGAGGATGGTAATTTTGTTAAATTGCCTGAAACTCTTGTTAATGGCTTTGGTATAAACATCATTCGCACAATGGAAACTACCTATTGTCGCGTTGGTGAGTGCTTGAAATCTAAGGCTGGTGTATGCTTTGGTGCTAATAGGTTCTTTGTTTACAATGATGACTTTGGTTCCGATTACATTTGTGGTAATGGACTGTTTTCTTTTGTTAAGAACCTGTTTAACACTTTCACAATGTCAGTGTCTGTCATGGCACTTTCAGGACAGGTCATTTTTAATTGCGCTGTTGCAGCTTTGGCAATATTTATTTGCTTTTTAGTTGTAAAATTTAAGCGCATGTTTGGTGACCTGTCTTATGGTGTTTGTAGTGTCATTGCTGCTGTAACTATCAATAACTTGTCTTATGTGTTTACACAAAACATGTTATTCATGTTTGTGTATGCAACATTCTACTTTTTGGCTGTCAGAAATCTTAATTATGCATGGATTTGGCATGCTAGTTATGTCGTTGCTTATTTCAACTTGGCGCCATGGTTTATTATCGTATGGTATGTTGTTGCAATGCTTACTGGTCTTTTGCCATCTGTCTTAAAACTTAAAATTTCTACCAATTTGTTTGAAGGTGACAAGTTTGTTGGTACATTTGAAAATGCAGCTTTTGGCACTTTTGTTATAGACATGCATTCGTATGAAAAACTTGTTAATAGTATTACACCTGATAAGCTTAAACAACACGCCGCTATGTTTAATAAGTATAAATATTATAGTGGTAGTGCTTCTGAGGCTGATTATAGATGCGCTTGTTTTGCACATCTAGCTAAGGCTATGACAGATTATGCATCAAGTCATCAAGACATGTTGTATTCACCTCCTAGCATTAGTTATAATTCAACTCTTCAAGCTGGTCTGCGTAAATTTGCGCAGCCTTCAGGTGTTATTGAACATTGCATTGTGCGCGTTAGCTATGGTAACATGGTTCTTAATGGTCTTTGGCTTGGTGATGAGGTTATTTGTCCTAGACATGTGATAGCCTCGTCTATCAATTCTGCCATTGATTATGACCATGAATACACTATGATGCGTTTACATAATTTCTCCGTGTCATCTGGTAATCTTTTTATTGGCGTAGTTAGTGCTAAAATGAGAGGTGCTTCTTTGGTTATTAAAGTTAACCAGAACAACCCTCATACGCCTAAACACGTCTTTAAAACGTTAAGAGCTGGTGATGCCTTCAATATATTGGCTTGTTATGATGGAGTACCCTCTGGTGTTTATGGTACCATCCTTAGACATAACAAAACTATTCGCGGTTCATTTATTAATGGCGCGTGTGGTTCACCTGGTTTTAACATTAATGGTGATACAGTTGAATTTGTTTACTTGCATCAGCTGGAACTTGGTAGTGGTTGCCATGTAGGGTCTAATATGGAAGGTGTTATGTACGGTGGTTTTGATGATCAGCCATCTCTTCAGATTGAAGGTGCTGATTGTTTGGTGACCGTCAATGTCATAGCATTTCTATATGGTGCCATACTTAATGGTTGCACATGGTTCCTTTCTAATGAACGTGTTAGTGCTGAAGTTTTTAATGGTTGGGCACATGATAATAATTTTACTGATGTTGGCAGTTTTGACTGTTTCAACATCTTGGCTGCTAAGACTGGTGTTGATGTTCAACGTATTCTTGCTTCTATTCAAAAACTAGCTAAAGGCTTTGGTGGTCGTAACATCATTGGATATGCATCACTCACTGATGAATTTACTGTCAGTGAGGTTGTTAAACAAATGTACGGCGTAAGTCTCCAGAGCAAACGTGTGCCTAGCATCTTTAATAATGTCACACTTGTTAGTGTGTTTTGGTCTATGTTTTTGTCAGAGCTTTTGTATTACACATCTAGCTATTGGATAAAACCAGACCTAATCACTGCTGTGTTTGTCTTGTTGTTTGGAATTGCTGTCATGCTCACACTTACTATTAAGCATAAAGTGTTGTTCTTGTACACATTCCTTATTCCAAGTGTTGTGATATCTGCTTGCTACAATTTGGCTTGGGATCTTTACATTCGTGAGCTTCTTGCCAAGTATTTTGACTACCATATGTCTATTTTTAGTATGGACATTCAAGGTTGTTTCAATATTGTTGCTTGTATTCTCGTTAATGCGATTCACACATGGAGATTTGTCAAGACAGGTACTGCTACAAGATTGACATATGTGTTGTCACTGGTTGTGTCAGTTTATAATTACTGGTGTTGCGGTGACTTCTTGTCTCTTTCAATGATGGTCCTACTTAATATCAATAATAATTGGTATATTGGTGCGATTGCTTACAGATTTTCTGTTGTTGTCGTTAACTATATGGATCCATCTGTTATAAGAATGCTTGGCGGTGTGAAAGTCATACTTTTCATGTATGTTACTTGTGGTTATTTATGCTGTATGTATTATGGCATATGCTACTGGTTTAACCGCTTCTTTAAGTGCACAATGGGACTTTATGAATTTAAAGTTAGTCCCGCTGAATTTAAGTACATGGTTGCTAATGATCTTCGTGCTCCTACAGGTGTTTTTGATTCAATGTCACTTAGTCTGAAGCTTATGGGTCTGGGCGGTGAGAGAACTATTAAGATCTCCACTGTACAGTCTAAATTGACCGATATTAAATGTACTAATGTTGTACTCATGGGCTGTCTCTCTAGTATGAACATTGAAGCTAATTCTAAAAAGTGGTCATATTGTGTTGATCTTCATAATAAGATTAACCTGTGTGATGATGCTGAGAAAGCTATGGAATATTTGCTTGCACTTGTGACATTTTTCATAAGTGAACATGCTGATTTTAATGTTTCAGAGCTTGTAGATTCATATTTTGGTGATAATAGCATACTTCAAAGTGTTGCTTCTACATTTGTTAATATGCCTTCGTTTATAGCTTACGAGAGTGCTCGTCAAAGTTATGAAGAGGCTATTAATAATGGATCATCACCTCAGCTCGTCAAACAACTTAAGCGTGCTATGAACATAGCCAAAGCTGAGCTTGATCACGAGTCATCTGTTCAACGTAAGCTTAATCGCATGGCCGAACAAGCTGCTGCACAGATGTACAAGGAAGCTAGAGCTGTTAACAAGAAGTCAAAAGTCATAAGTTCACTGCACACACTTCTGTTTGGAATGTTGCGTAAACTTGACATGTCTTCTGTAGATAACATACTAAGCCTTGCTCGTGATGGAGTTGTACCACTTTCTATTATACCTGCAGCATGTGCTACAAAACTTACCATAGTTGTGAGTGATTTTGAGTCATTCAAGCGCATCTTTCAACTAGGTAATGTTCAGTATGCAGGTGTGGTTTGGAGTCTTACCGAAGTTAAAGATAACGATGGAAAACCTGTTCACATAAAAGAAATTACTGCAAATAATACTGCTTTGACATGGCCTTTAATCCTTAATTGTGAGAGGATTGTTAAGCTTCAGAATAATGAGGTTATTCCTGGTAAGCTTAAGGTACGTCCACTTAAGGGTGAAGGTGAAGGTGGTTTTACTGCTGATGGAAAAGCATTATTTAATAATGAAGGTGGCAAAACTTTCATGTATGCTTTCATTGCAGATAAACCAGACCTTAAAGTAGTCAAGTGGGAATTCGATGGTGGTTGTAATGTCATTGAACTTGAACCTCCTTGTCGATTTGCAGTTGTTGATGCAGGTGGTAATAATGTTGTTAAATACCTGTACTTTGTTAAAAATCTCAATACCTTGCGGCGTGGTGCTGTGCTCGGTTTTATTGGAGCTACAGTTCGCCTTCAGGCTGGCAAACAAACAGAGCTTGTTGTTAACTCTTCTTTGTTGACGTTATGCTCTTTTGCTGTTGATCCTGCAAAATGTTATTTGGACGCTGTTAAAAGTGGTGTTAAACCTGTTAACAATTGTGTTAAAATGCTTTCTAATGGTTCTGGTACTGGTCAAGCTGTTACCGTAGGTGTCGAAGCCAATACTAATCAGGATAGTTATGGTGGTGCTTCTGTTTGTTTATATTGCAGAGCTCATGTTGACCATCCTAGTATTGATGGATTCTGTCAATTTAAAGGCAGATATGTCCAAATACCCGTAGGTACTGTTGACCCTATACGGTTTTGTCTTGAAAATCAAGTTTGCAAAGTGTGTCATTGTTGGTTGAATAATGGCTGTTCTTGTGGTAGAACGTCAGTTATCCAATCTGTTGATCAGGCTTATTTAAACGAGCAAGGGGCTCTAGTGCAGCTCGACTAG
Protein
MSSNLVTLAFASDSEISAEGFCDVSSAVYAFSVSAANGFTDCRFVAQGLEHCLVGIEADDYVLCVTGDVQLKAYIAKFSDRPLNLRGWIVRSNSNYFLETMDLVFGCGGGTSIPVDNYMCGANGKPVLPEDMWCFCDYFGDDGDNITVNGQAYHKAWNVTRGDVPYQFQNASTILSIEYLADEKHVLPDGAVAKSAKPPKFSKNIVLSEKYKALYDACGNPFVTNGTNVLEVVTNPIFAHGFVQCKCGSKHWTTGDWAGFKSVCCGIPGRVLCTVFGGVAPGSVLLTSTRVDASPGATRYYHGLTLKHICNVDGVACWRVTKVQGVECFVASGSIEDCVGSTFDTCTYDNYTSFAKAFKCGMLTGSFSDNVVASVINGTLDVGLAVLDVTTAVTKPWFVLKCGSLLESAWDALIMAIKQLPVMASDVLKFFNNLTQVLIVVRNGVIDIIHSVPEAFKSAFEIFKDLVTGVFDLVVDHFKIANKKFKRAGDYILFENALACLVSGKIKGVKQAGLKKLLYAKAIVGATVKVTVNRIESATVKLVECKPSNFVKKGSAVVINNIAFFHSDGVYRLMSDSDEVYEDIAFTAESVSTVKKPVFDCTKPVDFPDISSTDVEVLVREVRATLGKFSRVYDKYNCVVKDGKCVVTHRYVFNAPSFVEDKAIFVDLCKDYVADVGFEAFYANAIVANNSDEFNPVYSAFEVFKTKVECPEEFMNIDGGSIFGTFINTVNDAVNFVKSLKITVTATEVMINTVKRFKRFASALAKLYSEFMNTVKNIISIGSIKCYHYGFVKPVLVIKDIFYRIYDAAVDTFNVAVEAGLNTVKTFSGGENPITFSRVEVASVELEHAEYVKPEANGHVSVINGHTFYTCGDYYYPCDQNNCFSQCFKKVGGSAVTFSEKVAVKQIDPVYKVKLVFEFEDDTISSVCKQAIGKYISFEGNDWSSFEETIHNAMNVVGEFVDLPDYFIYDEEGGHDLTNTVMISQWPVFDPSALQLLVADLGVNCDFNGKSSIEECLTSVSDTVLCVSLEKSCDCGTFNAIMEGFALDFKPCTDSDVCDNCGGFCTTTVLSMTGTGFVRSCDEPLMPFNVTFEGYGVYKNVCFVNDTVLPPPFDEEITPIEEDLVVEDVITADEVVDVETTAQVEEVTVVSAIEEDIIKPEEVIDVSSDIEAVNHALSFMKPTETKFVDPFKFDYYDHEGIRVLRQNNNNCWVASTLVQLQLSCLLDDDDTMALFKAGSVSPLVRKCYDAVGAIVGSLGDASHCLEVLLKDLHTMFITCDATCGCGSSNYELTGSVFRFMPTRDSFSYGACGVCGKTLKLKIRTMTGTGFFCQDPKPFNTARAIVKPVCASIYQGSTTSGHYKTNVFGKRFCVDGSGVSSISNGHINTILLKDCNYGISAIAEPKQEKVEQFVTPEDVGQVVKQKPKPFTIYRNIEFYQGDVSELVGLDFDFIVNAANENLKHAGGVAAAIDKLTGNELQSLSNKYVKTNGKVKVGSSAMIRCKKYSVLNVVGPRKGKHAPDLLEKCYRTILKEQGVPLTPLISVGIFGIPLATSFNALLNTSSGRTVRCFCYTDKECNEIKTLVASLNEEQVAATVEETVVAEEKPIADLETAVERPAEEKSVEAEKIATEEVKEPLVAEKVIVEVNEPVLKVAGVSYYNIEDSFAVGADNIVILTNSKLELGKIGECIDKHSDGALKLAVSEYLSQTPNVPPGNVISMRCSGLATVVFAVVPSDGDVQYVRNVKRTISKLSKLKGSSVCSFSTLDMHKRLLNLFNKFCVDNIDDIKDIHDTKTTIKVSLDGRNVVDVDVAADQTIGEQLNACTTDNVIISDSVVTDVIDTIVNVAPEVDWDSFYGFPHAAEFHMLDHSAFAFDNDVVDGKRALVGTDNNCWINAVCLQLQFAEVDFTSEGLKDMWNEFLVGNVAKFCHWIYWLVRANKGDAGDAENALNMLNKYVKAHGTVTLTRETAEGCCVNEHRINSFVVNASVLRSGCNDGYCKHGNAYIARVSKVDGVSVIVNVDRPSVMSDNLLLSGTSYTAFSGPMDSGHYRVFNPATSKMFDGANCIGGDLCNLAVTAVVIKNKVFKIQTADNNTPVKIIKKLDDASEKFFSFGDIVSKNVCNSIIWFFTMLSIIFRAFKTRDFKVFALAPERTGVILSRSLKYNLKAAQHVLRRKQTYVERFFKFSVIAYTLYALSFMFVRFSPANDYFCKDHVEGYSNSTFVKDEYCASTMCKVCLLGFQELADLPHTKVVWKYVGFPIFVNWLPFLYLAFLFTFGGIFVKGLVCYFFAQYVNTLGVYFGMQEKFWPLQIIPFDIFGDEIVVTFIVYKALMFIKHVCFGCEKPSCVACSKSARLNRVPMQTIVNGANKLFYVVANGGSSYCHKHKFFCLNCDSYGPGNTFINETVARELSNVVKTNVQPTGESFIEVDKVSFENGSYYLYSGETFWRYNFDVTEAKYGCKEVLKNCNVLSDFIVYNNTGTNVSQIRNACVYFSQMLCKPIKLVDATLLSTLNVDFNGALHSAFVQVLNDSFSKDLSSCASMTECKQALGFDVSDEEFVDAVSNAHRFNVLLSDNSFNNLLTSYAKPEEQLSTHDVATCMRFNAKVVNHNVLIKENVPIVWLARDFQQLSEEGRKYLVKTTKAKGVTFLLTFNTNAMNVKLPAISIVNKKGAGVSSSFLWWLCAAIITFFFCVGISEGLIATSLEGFGFKYIKDGVMHDFDKPLSCVHNVFDNFNSWHEARFGSIPSNSLKCPIVVGTLDDVRNVPGVPSGILLVGKTLVFAIKAVFTDAGNCYGLNGLTNAGACLFNSACTKLEGLGGTHVYCYKDGLFEGSKRYSDLVPHSNYKMEDGNFVKLPETLVNGFGINIIRTMETTYCRVGECLKSKAGVCFGANRFFVYNDDFGSDYICGNGLFSFVKNLFNTFTMSVSVMALSGQVIFNCAVAALAIFICFLVVKFKRMFGDLSYGVCSVIAAVTINNLSYVFTQNMLFMFVYATFYFLAVRNLNYAWIWHASYVVAYFNLAPWFIIVWYVVAMLTGLLPSVLKLKISTNLFEGDKFVGTFENAAFGTFVIDMHSYEKLVNSITPDKLKQHAAMFNKYKYYSGSASEADYRCACFAHLAKAMTDYASSHQDMLYSPPSISYNSTLQAGLRKFAQPSGVIEHCIVRVSYGNMVLNGLWLGDEVICPRHVIASSINSAIDYDHEYTMMRLHNFSVSSGNLFIGVVSAKMRGASLVIKVNQNNPHTPKHVFKTLRAGDAFNILACYDGVPSGVYGTILRHNKTIRGSFINGACGSPGFNINGDTVEFVYLHQLELGSGCHVGSNMEGVMYGGFDDQPSLQIEGADCLVTVNVIAFLYGAILNGCTWFLSNERVSAEVFNGWAHDNNFTDVGSFDCFNILAAKTGVDVQRILASIQKLAKGFGGRNIIGYASLTDEFTVSEVVKQMYGVSLQSKRVPSIFNNVTLVSVFWSMFLSELLYYTSSYWIKPDLITAVFVLLFGIAVMLTLTIKHKVLFLYTFLIPSVVISACYNLAWDLYIRELLAKYFDYHMSIFSMDIQGCFNIVACILVNAIHTWRFVKTGTATRLTYVLSLVVSVYNYWCCGDFLSLSMMVLLNINNNWYIGAIAYRFSVVVVNYMDPSVIRMLGGVKVILFMYVTCGYLCCMYYGICYWFNRFFKCTMGLYEFKVSPAEFKYMVANDLRAPTGVFDSMSLSLKLMGLGGERTIKISTVQSKLTDIKCTNVVLMGCLSSMNIEANSKKWSYCVDLHNKINLCDDAEKAMEYLLALVTFFISEHADFNVSELVDSYFGDNSILQSVASTFVNMPSFIAYESARQSYEEAINNGSSPQLVKQLKRAMNIAKAELDHESSVQRKLNRMAEQAAAQMYKEARAVNKKSKVISSLHTLLFGMLRKLDMSSVDNILSLARDGVVPLSIIPAACATKLTIVVSDFESFKRIFQLGNVQYAGVVWSLTEVKDNDGKPVHIKEITANNTALTWPLILNCERIVKLQNNEVIPGKLKVRPLKGEGEGGFTADGKALFNNEGGKTFMYAFIADKPDLKVVKWEFDGGCNVIELEPPCRFAVVDAGGNNVVKYLYFVKNLNTLRRGAVLGFIGATVRLQAGKQTELVVNSSLLTLCSFAVDPAKCYLDAVKSGVKPVNNCVKMLSNGSGTGQAVTVGVEANTNQDSYGGASVCLYCRAHVDHPSIDGFCQFKGRYVQIPVGTVDPIRFCLENQVCKVCHCWLNNGCSCGRTSVIQSVDQAYLNEQGALVQLD
Summary
Similarity
Belongs to the coronaviruses polyprotein 1ab family.
Uniprot
Pubmed
EMBL
Proteomes
Pfam
Interpro
IPR037204
NSP7_sf
IPR014828 NSP7
IPR038123 NSP4_C_sf
IPR013016 Peptidase_C30/C16
IPR009003 Peptidase_S1_PA
IPR008740 Peptidase_C30
IPR036333 NSP10_sf
IPR002589 Macro_dom
IPR014827 Viral_protease
IPR014829 NSP8
IPR037230 NSP8_sf
IPR011050 Pectin_lyase_fold/virulence
IPR036499 NSP9_sf
IPR018995 RNA_synth_NSP10_coronavirus
IPR014822 NSP9
IPR032505 Corona_NSP4_C
IPR014828 NSP7
IPR038123 NSP4_C_sf
IPR013016 Peptidase_C30/C16
IPR009003 Peptidase_S1_PA
IPR008740 Peptidase_C30
IPR036333 NSP10_sf
IPR002589 Macro_dom
IPR014827 Viral_protease
IPR014829 NSP8
IPR037230 NSP8_sf
IPR011050 Pectin_lyase_fold/virulence
IPR036499 NSP9_sf
IPR018995 RNA_synth_NSP10_coronavirus
IPR014822 NSP9
IPR032505 Corona_NSP4_C
SUPFAM
Gene 3D
ProteinModelPortal
PDB
6NUS
E-value=0,
Score=3005
Ontologies
GO
GO:0019082 P:viral protein processing
GO:0003723 F:RNA binding
GO:0033644 C:host cell membrane
GO:0008242 F:omega peptidase activity
GO:0004197 F:cysteine-type endopeptidase activity
GO:0016021 C:integral component of membrane
GO:0039520 P:induction by virus of host autophagy
GO:0008270 F:zinc ion binding
GO:0003968 F:RNA-directed 5'-3' RNA polymerase activity
GO:0044220 C:host cell perinuclear region of cytoplasm
GO:0019079 P:viral genome replication
GO:0003723 F:RNA binding
GO:0033644 C:host cell membrane
GO:0008242 F:omega peptidase activity
GO:0004197 F:cysteine-type endopeptidase activity
GO:0016021 C:integral component of membrane
GO:0039520 P:induction by virus of host autophagy
GO:0008270 F:zinc ion binding
GO:0003968 F:RNA-directed 5'-3' RNA polymerase activity
GO:0044220 C:host cell perinuclear region of cytoplasm
GO:0019079 P:viral genome replication
Subcellular Location
From MSLVP
Capsid
From Uniprot
Host cytoplasm
Host perinuclear region
Host membrane
Host perinuclear region
Host membrane
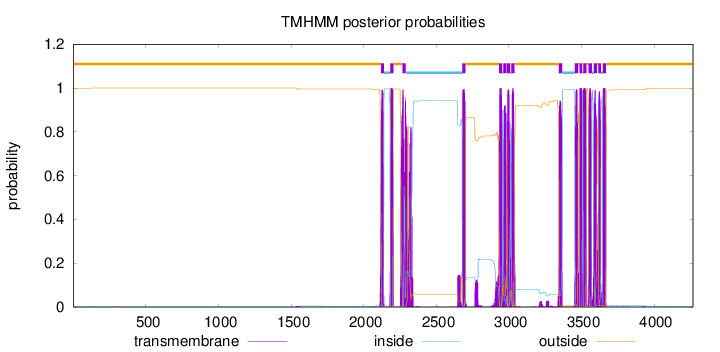
Topology
Length:
4268
Number of predicted TMHs:
16
Exp number of AAs in TMHs:
390.17964
Exp number, first 60 AAs:
0.00251
Total prob of N-in:
0.00054
outside
1 - 2119
TMhelix
2120 - 2139
inside
2140 - 2182
TMhelix
2183 - 2205
outside
2206 - 2267
TMhelix
2268 - 2290
inside
2291 - 2678
TMhelix
2679 - 2701
outside
2702 - 2932
TMhelix
2933 - 2955
inside
2956 - 2961
TMhelix
2962 - 2984
outside
2985 - 2987
TMhelix
2988 - 3010
inside
3011 - 3016
TMhelix
3017 - 3039
outside
3040 - 3344
TMhelix
3345 - 3367
inside
3368 - 3454
TMhelix
3455 - 3477
outside
3478 - 3486
TMhelix
3487 - 3506
inside
3507 - 3512
TMhelix
3513 - 3535
outside
3536 - 3549
TMhelix
3550 - 3572
inside
3573 - 3584
TMhelix
3585 - 3607
outside
3608 - 3616
TMhelix
3617 - 3634
inside
3635 - 3646
TMhelix
3647 - 3669
outside
3670 - 4268
Population Genetic Test Statistics
Genomic alignment in the CDS region
Multiple alignment of Orthologues
Orthologous in Strains
| Strain | Availability | Status | Gene |
|---|---|---|---|
| CHINA_HS_2019_MN908947 | |||
| CHINA_AVIAN_2008_NC_016995 | |||
| CHINA_AVIAN_2007_NC_016991 | |||
| CHINA_MURINE_2015_NC_035191 | |||
| CANADA_AVIAN_2007_NC_010800 | |||
| USA_PIG_2000_NC_038861 | |||
| CHINA_AVIAN_2007_NC_011549 | |||
| ITALY_PIG_2009_NC_028806 |
Protein |
YP_009199241.1 |
|
| GERMANY_PIG_2012_LT545990 | |||
| CHINA_AVIAN_2007_NC_016992 | |||
| CHINA_BAT_2005_NC_009657 | |||
| CANADA_HS_2003_NC_004718 | |||
| CHINA_BAT_2014_NC_030886 | |||
| CHINA_BAT_2005_NC_018871 | |||
| USA_MURINE_2009_NC_012936 | |||
| CHINA_RABBIT_2006_NC_017083 | |||
| UK_PIG_2000_NC_003436 | |||
| ROMANIA_PIG_2015_LT898435 | |||
| ROMANIA_PIG_2015_LT898436 | |||
| GERMANY_PIG_2015_LT898444 | |||
| GERMANY_PIG_2015_LT898414 | |||
| GERMANY_PIG_2015_LT898439 | |||
| GERMANY_PIG_2015_LT898413 | |||
| GERMANY_PIG_2015_LT898412 | |||
| GERMANY_PIG_2015_LT898411 | |||
| GERMANY_PIG_2015_LT898416 | |||
| GERMANY_PIG_2015_LT898443 | |||
| GERMANY_PIG_2015_LT898420 | |||
| GERMANY_PIG_2015_LT898408 | |||
| GERMANY_PIG_2015_LT898423 | |||
| GERMANY_PIG_2015_LT898432 | |||
| GERMANY_PIG_2015_LT898409 | |||
| GERMANY_PIG_2015_LT898425 | |||
| GERMANY_PIG_2015_LT898446 | |||
| GERMANY_PIG_2014_LT898438 | |||
| GERMANY_PIG_2014_LT898440 | |||
| GERMANY_PIG_2014_LT900501 | |||
| GERMANY_PIG_2014_LT898427 | |||
| GERMANY_PIG_2014_LT898415 | |||
| GERMANY_PIG_2014_LT898421 | |||
| GERMANY_PIG_2014_LT898431 | |||
| GERMANY_PIG_2014_LT898410 | |||
| GERMANY_PIG_2014_LT900498 | |||
| GERMANY_PIG_2014_LT898430 | |||
| GERMANY_PIG_1978_LT897799 | |||
| GERMANY_PIG_2014_LT898447 | |||
| GERMANY_PIG_2014_LT898426 | |||
| GERMANY_PIG_2014_LT898417 | |||
| GERMANY_PIG_2014_LT900500 | |||
| GERMANY_PIG_2014_LT898445 | |||
| AUSTRIA_PIG_2015_LT898418 | |||
| AUSTRIA_PIG_2015_LT898441 | |||
| AUSTRIA_PIG_2015_LT898433 | |||
| AUSTRIA_PIG_2015_LT900502 | |||
| GERMANY_PIG_2015_LT900499 | |||
| BELGIUM_PIG_1980_LT906620 | |||
| BELGIUM_PIG_1977_LT905450 | |||
| SWITZERLAND_PIG_2003_LT905451 | |||
| BELGIUM_PIG_1978_LT906581 | |||
| UK_PIG_1987_LT906582 | |||
| CHINA_PIG_2009_NC_016990 | |||
| CHINA_PIG_2010_NC_039208 | |||
| KENYA_BAT_2010_KY073745 | |||
| KENYA_BAT_2010_NC_032107 | |||
| CHINA_AVIAN_2007_NC_016994 | |||
| EUROPE_MURINE_2004_AY700211 | |||
| CHINA_AVIAN_2007_NC_011550 | |||
| USA_MURINE_1997_NC_001846 | |||
| USA_MURINE_1998_NC_023760 | |||
| MID_EAST_HS_2012_NC_019843 | |||
| CHINA_AVIAN_2007_NC_016993 | |||
| CHINA_MURINE_2013_NC_032730 | |||
| USA_HS_2004_AY585228 | |||
| NETHERLAND_HS_2004_NC_005831 | |||
| CHINA_HS_2004_NC_006577 | |||
| EUROPE_HS_2000_NC_002645 | |||
| NETHERLAND_FERRET_2010_NC_030292 | |||
| JAPAN_FERRET_2013_LC119077 |
Protein |
BAV31348.1 |
|
| USA_FELINE_2005_NC_002306 | |||
| CHINA_MURINE_2011_NC_034972 | |||
| CHINA_AVIAN_2007_NC_016996 | |||
| ARABIA_CAMEL_2015_NC_028752 | |||
| CHINA_AVIAN_2007_NC_011547 | |||
| CHINA_BAT_2012_NC_028824 | |||
| CHINA_BAT_2013_NC_028814 | |||
| CHINA_BAT_2013_NC_028833 | |||
| CHINA_BAT_2011_NC_028811 | |||
| USA_BOVIN_2001_NC_003045 | |||
| CHINA_MURINE_2012_NC_026011 | |||
| GERMANY_ERINACEINAE_2012_NC_022643 | |||
| GERMANY_ERINACEINAE_2012_NC_039207 | |||
| UK_HS_2012_NC_038294 | |||
| AMERICA_WHALE_2007_NC_010646 | |||
| CHINA_BAT_2013_NC_025217 | |||
| UGANDA_BAT_2013_NC_034440 | |||
| CHINA_BAT_2006_NC_009021 | |||
| CHINA_BAT_2008_NC_010438 | |||
| CHINA_BAT_2006_NC_009020 | |||
| CHINA_BAT_2006_NC_009019 | |||
| CHINA_BAT_2006_NC_009988 | |||
| USA_BAT_2006_NC_022103 | |||
| BULGARIA_BAT_2008_NC_014470 | |||
| CHINA_BAT_2008_NC_010437 |
Protein Protein |
YP_001718603.1 YP_001718604.1 |
|
| USA_AVIAN_2004_NC_001451 |
Copyright@ 2018-2023
Any Comments and suggestions mail to:
zhuzl@cqu.edu.cn,
mg@cau.edu.cn
渝ICP备19006517号

渝公网安备 50010602502065号
In processing...
Login to ASFVdb
Email
Password
Please go to Regist if without an account.
If you have forgotten your password, you can once again Regist an account with a registed or new email.
If you have forgotten your password, you can once again Regist an account with a registed or new email.
Change my password
Enter new password
Reenter new password
Regist an account of ASFVdb
It is required that you provide your institutional e-mail address (with edu or org in the domain) as confirmation of your affiliation.
Enter email
Reenter email
First Name
Last Name
Institution
You can directly go to Login if with an account.
Registraion Success
Your password has been sent to your email.
Please check it and login later.
Welcome to use ASFVdb.
Please check it and login later.
Welcome to use ASFVdb.