Strain
shrimp_NC_010306
(Region: Australia; Strain: Gill-associated virus, complete genome.; Date: 1996)
Gene
polyprotein precursor
Description
Annotated in NCBI,
polyprotein precursor
Location
GenBank Accession
Sequence
CDS
ATGCAATGTTCGCGATCATCCACCATGCTCTCCTTCTCCTCACACTTCCCAGCCTCATTATCTTTTACTGGGCTGCGGGGTATATTTCTGATCTTCCTCTTGTCTTCAGCACTCTTTGGATCTGGGGCTCATGGCTTTGCACTACAATTTGCTACTCCCTCACGTTCTCTGGACGCAGGCGCAATAAGGACAAATTCTACTATTCTATCAACGTGCAACAACACAATCCATACAGTAAAAGAATCATGTCATCTAAGCTCGCTTGAGTCTTCGGTGAACTGTTTCAATAATGAACACACACATGATACCTCAGCTCCAGGTTCACATATCATCTACACAGTTGGTTTTGCATATCTAAAAACCGATTATGAGTGTAAGGAAGGATATCCACCTGCCCACACCGTGCAACGATCCTTTCTCACTATCCTCTATCTCATTATCTGTTCTCTCCTTGCCTATATCTTCACTAAGCTAACTCCTATCGCTAAATCCTTCATCGCTTCATGCTTCCTAACTGAACACATCTTGGAAACAACTGAAACTGAAAAGGGACAGCTAACCATAGCTCACGATCGGCATAGACTCGCGCCAACAAGTTGGTATTCTATCTTCAACACATCACTTAATTTCCTTCTAATTATCCTCTTCATACTACTCTGTCTTCTCATCACACCCACGTTTGCTAAGGAGCCTGAAACATTATTTTCAAGCAATCACACTGAACCTTACGACTGCATGTTTTGGGCTGCAAATGGCGACTGTACATGTAACGCCACAAATTGCGATTGGAGTGAGCTAGTCCAACAGCTCTGCCCACACACATGCAATTCAGGCACATCACCACCACCACCACCCACTACAGCCCAAAATTCAACATCTCCATGCTCCGCAGACGATTCAACCGGATGCTTTAAATATCTTTATGATTACAGCGAATCTAAATTAACACACGCTATCAAATACGTCCATTCAATTGGCTCAATCTCAGTTAGATCCACCACAATAACATCTGATCAACTCGAATCCCTCTCCATAGATGAGGCCAGATATTCAGAAATTGCAAAATTATATAGAATCGGTAATAGCACATCAGCATTAGGCTGTGTTTACAACCCAGCTTCATATTACCTTCATGGCGATGCAATCCCCATCACCTGTCCGCCAACACCCCGGATCTTAGGTACAACATATCGCCATAGCATAGGAAAGCAAATTCTTTATAATAATAAAATGGTTAATGTCACTGTTGATCAGCGCTGTAAATCACATTCAGAAAATTGTTGGGCTTATTATAATAAAGTTTCAAAAGGTATCTTCATCCAATTTCATCCAACTTATGCACACCAATATCATAAGAAAACGCTGAAGCCCACTACACTAATCACACCTTTCTACCCTCCTCGTGATACACGTACTCTCGCTACACATCTTGGTCCTAGAGTTATCCGTAATGAGGGCGATTATCAGATATTTTTAGAACCGGGTGGGCTTGGCAGAACATATTTTGATGGATATCCCTACAATGAAATTTATGCATCCACACGTGCCGATTGTGAATATAACACGATGAGCAACGCTAATAAGGTCGGAATTAATCTCGGTGATGACATTTTGCACGAGACAATCCCAACACCTAGTGGATACGCTGTCAGTGTGGTCACTTGTGGTACAACTTTCACATATATGAAATTAGATAATTTAGTTAAATTCCAATGGGAGCAAGTTCAATACACCGATATAGATGATATACCTGCTGGCTTTCGTGACCCATATGACTTTTCCGTCGAGACCCCCAGCGGGCCTGTTACTATCAGTGTCCTCGAAGAGTATCACGACGGTGACTCCATTCAGGAAACAGCACCAAAGCGGTTCTTCATCTATTATCGTGTAATGACAGCTCGCCTTACCCCATCCCAAATACAATATCTCAACGAATCAATCCATCAAACAGGACTTTGGTCAGCTGCATATCCTTTCCAAAACTGTTACGTCACTAGACCTGAATTCGCAAAAACTACACATCCATATTCATTCGCACTCTCCTATAGTGACTTCTCCATCACAGCTGGCCCACTCGTTGAATGTAACGATTGGAACATTCAAATGCATCTGCCTTTAGCATCATCAGGTTCAGTTAAGCGTACCTGGGCTGGTGAATTTAGACATCTCCCCCACTTTCTAACCAAACGTGGATTTTATCCCCTAGAACCAGTAACTGAAAATGCAATTGATTATTTAATAGTTGAATATAATGCCCACGCATCACGCTACTCCCATCAAGCCACATACCATCAATTCGGTCATCCTGTTGCCAAGGCTCAAACAATGCCCGGCGTTTGTCCAACACCTCGCTCACTACGCTACAAAGGTCTCTGCTATGAGGTCGACTGGTCAGTTCGCTCACCAGCTCCACCAATTAGCGGTTACCCTGATATCGGCACACACACATCCGGCTACATTTTCCAAAGATACGATTACTATCGATTCAAACCTAAATTTGGCAATGGATTATACCTTGGTAAAGTCTCAGCTGCAGCATCTATCGGTACGTATTCAAAATGTGGTAAAGCACAATCAATTGGTCCTTTCCATGATCATGGAATTATCACTGATATGGGCACTCCAGTTTATGACAGTATCTGTGATTCTGCAGCTTATACAATACCTGTGGTTAAATACAACAGCCCCTATTCCCTTGGTATTCCCGGTGTCACATGTAACATCAATGACACAACCCTAATATGTGGAACCAACAGCACTTTCAGATTTTCCATCTGTTCACACAAAATCCCATATGATGGCCCACACTCAGTCACATGCATTGACTCAGTAGATAATAAAGTCTATCTCACAAAAGAGCAGGGGCATTCATATTACATCGCTGGTGATCCAGGTTTTTTACACCTCTCACACAATAAGCATACCCCATATAATAGTATCCTTAAATCCCAATTCGACCTACTACATTTCTCCTACATCTATCAGGCTATTGCAGTATTACTTGGCAGTATCGGATACATTCTTCTTGCACTTTATCTACTACTCTTTATTCTCACAACCATCTGGGCCAACATCAAATACATATTCTACACTAAGACTACCTATCTCGGCTACACCATTCCAGAGCGATTTATGGCTGGCAAGTCAGGGTGTAAAATTTGTGGGCTTGATACCAAACACCTCAAAGTTCACGCCCGTCTTCACAAAATCTACATTCATAGCCCTATGCTTGGCCGGACATTCTTCCTCTGGTCCCCCATCTATATCATGGCATTATTCGCACTCCTAAGCCCTGCTTCGGCCTTAGCTCCCGGACAGGCGCGTGTTAGAGGTTCTCCCGCTACATTCAAATCAACCCCCGAGATTAAATCAACATCATGTTCTGGCAACCAGTGTCTCCTCGATCTTGAATATACTGGTGTCATTCCAATTTATGATGGTGCCCAATTTTCAGTTGACCTTAACATCGAAGGCTATCTCCCGGTCACAACTAGTTATGTAGTCCGTGATCCAAGTTACACCTCATCATGCGCTTATCTCTACACCTCTCTTCCACCTAAGCTCTGCGACGCTCGCATCAACTGGTCATGCCTCCACACCGGATCTTGCAAGAATAGTTCAGATTATCTTTTCAATCCTTTAGGTCAGCATACCTCAAACGATTATGTCGTCGCCAATCCATCCAATCCCCTCCAATGTGGCTTATGCCCCGTTTCAGCAGACTGCGACACCAGGTTTGCAGATTTCAATCACGGTTGCGCAACCATCAATGATGGCCACGCTGCTGGCGCCGCTTGGATTTCAGGGGACATCAACGGTGACATGATCGCAGCCTTTGAGTGTTCTATTAATAACATTGCATTCCAAATATGTGATCTCCAAACCAATGCCTGTACATCAATAACAACTGACTACAGAAATTATACAGCCGATTTTGAAACAATAAGCTTTAATATCGCTCATCCCCAGGTAGCAAAGACAACTTTCAAAGTTGGTGCGCTTTTTACCCAAGGCACGACATATCCTAAACATCTCTTTTATGACGTGCCCGGTAAATATGCCGCGCCTGCTGGATCATTCTTTAGTTATCAAGCTGAGACAGTTCCAACTGGTGACTTCTGCAATAACAACGCATGGATGTCGCCTGGCTTAGCAACAGCTGATATTAAATATGACGGATATCCAACTTTAGATTATAAATTAAATTTTGCAACAATCCAGCAAGCCATCCGTAGTTATGACCCACTTGGCGCTATAGTTCAATGTAATTATGATCAGGCATACATCTCAACAATCACATCCCGTCAGCAGCGATCGCTTAAATTAAATGGCGTTACATACAGCGATGAGGTTGATGCTCTATCGTATGGGCTGCTCCTTAATCCGCATCATTGCGATTTCGGAGCTGTTAACATACATTTTGCATATGCCGCCACCGCTCATGTCTCCATCATAGAAGGCGACCCTGACCAGCTTAAATTCAACTGTAAAGGCTGTCTTTTCACAAATAATCAAATGCAATGTTCCATCCAAGGCATAGATTCTCATTCATATCAAATCACTGATTCTCTCAACACTTTCGGCGCTTCCACTTGCTCTCACACTAAAGATTCTCACCTATGTAATTTCACTGCCTCGTCACCTGAGTTCACCCTTAGAGTTAACGGTAAACCAATCGCCATTACTGCAGTTGTTACGCAATGTGATGTCGGGGCTATCTCCGACACCATTGTGGGCGCTGCAGGAAATGACCGCTTCGGTACCTTCACCTCTTTTTCACTCGGTGGCATGACTTGGGATTATATCCTCAAATATATTCTCTATGGCATTGGCACACTCCTCCTTATCTTTTCTCTCTATTTCCTGCTACGGTTGCTTATCCACCTATGCACTACCATGAGAACGAAGGTTAAAAAGTCCTAG
Protein
MQCSRSSTMLSFSSHFPASLSFTGLRGIFLIFLLSSALFGSGAHGFALQFATPSRSLDAGAIRTNSTILSTCNNTIHTVKESCHLSSLESSVNCFNNEHTHDTSAPGSHIIYTVGFAYLKTDYECKEGYPPAHTVQRSFLTILYLIICSLLAYIFTKLTPIAKSFIASCFLTEHILETTETEKGQLTIAHDRHRLAPTSWYSIFNTSLNFLLIILFILLCLLITPTFAKEPETLFSSNHTEPYDCMFWAANGDCTCNATNCDWSELVQQLCPHTCNSGTSPPPPPTTAQNSTSPCSADDSTGCFKYLYDYSESKLTHAIKYVHSIGSISVRSTTITSDQLESLSIDEARYSEIAKLYRIGNSTSALGCVYNPASYYLHGDAIPITCPPTPRILGTTYRHSIGKQILYNNKMVNVTVDQRCKSHSENCWAYYNKVSKGIFIQFHPTYAHQYHKKTLKPTTLITPFYPPRDTRTLATHLGPRVIRNEGDYQIFLEPGGLGRTYFDGYPYNEIYASTRADCEYNTMSNANKVGINLGDDILHETIPTPSGYAVSVVTCGTTFTYMKLDNLVKFQWEQVQYTDIDDIPAGFRDPYDFSVETPSGPVTISVLEEYHDGDSIQETAPKRFFIYYRVMTARLTPSQIQYLNESIHQTGLWSAAYPFQNCYVTRPEFAKTTHPYSFALSYSDFSITAGPLVECNDWNIQMHLPLASSGSVKRTWAGEFRHLPHFLTKRGFYPLEPVTENAIDYLIVEYNAHASRYSHQATYHQFGHPVAKAQTMPGVCPTPRSLRYKGLCYEVDWSVRSPAPPISGYPDIGTHTSGYIFQRYDYYRFKPKFGNGLYLGKVSAAASIGTYSKCGKAQSIGPFHDHGIITDMGTPVYDSICDSAAYTIPVVKYNSPYSLGIPGVTCNINDTTLICGTNSTFRFSICSHKIPYDGPHSVTCIDSVDNKVYLTKEQGHSYYIAGDPGFLHLSHNKHTPYNSILKSQFDLLHFSYIYQAIAVLLGSIGYILLALYLLLFILTTIWANIKYIFYTKTTYLGYTIPERFMAGKSGCKICGLDTKHLKVHARLHKIYIHSPMLGRTFFLWSPIYIMALFALLSPASALAPGQARVRGSPATFKSTPEIKSTSCSGNQCLLDLEYTGVIPIYDGAQFSVDLNIEGYLPVTTSYVVRDPSYTSSCAYLYTSLPPKLCDARINWSCLHTGSCKNSSDYLFNPLGQHTSNDYVVANPSNPLQCGLCPVSADCDTRFADFNHGCATINDGHAAGAAWISGDINGDMIAAFECSINNIAFQICDLQTNACTSITTDYRNYTADFETISFNIAHPQVAKTTFKVGALFTQGTTYPKHLFYDVPGKYAAPAGSFFSYQAETVPTGDFCNNNAWMSPGLATADIKYDGYPTLDYKLNFATIQQAIRSYDPLGAIVQCNYDQAYISTITSRQQRSLKLNGVTYSDEVDALSYGLLLNPHHCDFGAVNIHFAYAATAHVSIIEGDPDQLKFNCKGCLFTNNQMQCSIQGIDSHSYQITDSLNTFGASTCSHTKDSHLCNFTASSPEFTLRVNGKPIAITAVVTQCDVGAISDTIVGAAGNDRFGTFTSFSLGGMTWDYILKYILYGIGTLLLIFSLYFLLRLLIHLCTTMRTKVKKS
Summary
Uniprot
Pubmed
EMBL
Proteomes
ProteinModelPortal
Ontologies
Subcellular Location
From MSLVP
Capsid
Topology
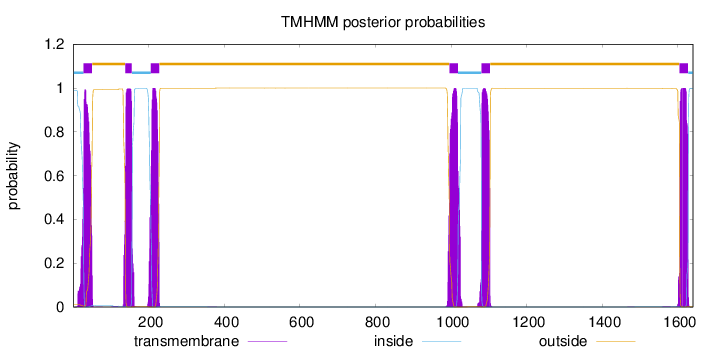
Length:
1640
Number of predicted TMHs:
6
Exp number of AAs in TMHs:
136.58163
Exp number, first 60 AAs:
22.28071
Total prob of N-in:
0.98947
POSSIBLE N-term signal
sequence
inside
1 - 27
TMhelix
28 - 50
outside
51 - 137
TMhelix
138 - 155
inside
156 - 205
TMhelix
206 - 228
outside
229 - 995
TMhelix
996 - 1018
inside
1019 - 1080
TMhelix
1081 - 1103
outside
1104 - 1604
TMhelix
1605 - 1627
inside
1628 - 1640